搜尋引擎可以偵測人工智慧內容嗎?

搜尋引擎可以偵測人工智慧內容嗎?
探索人工智慧在搜尋中產生的內容的複雜性,以及Google的長期目標如何影響其對該技術的反應。
去年人工智慧工具的爆炸性成長對數位行銷人員產生了巨大影響,尤其是SEO領域的行銷人員。
鑑於內容創建耗時且成本高昂,行銷人員轉向人工智慧尋求幫助,但結果好壞參半
儘管存在道德問題,但反覆出現的一個問題是:“搜尋引擎可以檢測到我的人工智慧內容嗎?”
這個問題被認為特別重要,因為如果答案是否定的,那麼關於是否以及如何使用人工智慧的許多其他問題就變得無效。
機器生成內容的悠久歷史
雖然機器生成或輔助內容創建的頻率是前所未有的,但這並不是全新的,也並不總是負面的。
對於新聞網站來說,首先報導新聞是當務之急,他們長期以來一直利用股票市場和地震儀等各種來源的數據來加快內容創作。
例如,發布一篇機器人文章實際上是正確的:
- 「今天早上[時間]/[日期]在[地點、城市]檢測到[震級]地震,這是自[上次事件日期]以來的第一次地震。更多消息敬請關注。
這樣的更新對於需要盡快獲取此資訊的最終讀者也很有幫助。
另一方面,我們看到了許多機器生成內容的“黑帽”實現。
多年來, Google一直在「自動生成不提供附加價值的頁面」的旗幟下譴責使用馬可夫鏈來產生文字以輕鬆旋轉內容。
特別有趣的是「無附加價值」的含義,這對某些人來說主要是一個混淆點或灰色地帶。
LLM 如何增加價值?
由於 GPTx大語言模型(LLM) 和經過微調的人工智慧聊天機器人ChatGPT引起的關注,人工智慧內容的受歡迎程度飆升,後者改善了對話互動。
在不深入研究技術細節的情況下,關於這些工具有幾個要點需要考慮:
生成的文字基於機率分佈
- 例如,如果您寫道,“成為 SEO 很有趣,因為…”,法學碩士會查看所有標記,並嘗試根據其訓練集計算下一個最可能的單字。總的來說,您可以將其視為手機預測文字的真正高級版本。
ChatGPT 是一種生成式人工智慧
- 這意味著輸出是不可預測的。有一個隨機元素,它可能對相同的提示做出不同的反應。
當您理解這兩點時,您會發現像 ChatGPT 這樣的工具沒有任何傳統知識或「知道」任何東西。這個缺點是所有錯誤或所謂的「幻覺」的基礎。
大量記錄的輸出證明了這種方法如何產生不正確的結果並導致 ChatGPT 反覆自相矛盾。
考慮到頻繁產生幻覺的可能性,這引發了人們對人工智慧書寫文本「增值」的一致性的嚴重懷疑。
根本原因在於法學碩士產生文本的方式,如果沒有新的方法,這個問題就很難解決。
這是一個至關重要的考慮因素,特別是對於「你的金錢,你的生活」(YMYL) 主題,如果不準確,可能會嚴重損害人們的財務或生活。
今年,Men’s Health和CNET等主要出版物被發現發布了人工智慧生成的與事實不符的信息,凸顯了這一擔憂。
出版商並不是唯一面臨這個問題的人,因為 Google 很難用 YMYL 內容來控制其搜尋生成體驗 (SGE) 內容。
儘管谷歌表示將謹慎生成答案,並具體給出了一個例子“不會顯示有關給孩子服用泰諾的問題的答案,因為它屬於醫療領域”,但SGE 顯然會這樣做只需簡單地問它這個問題即可。
Google 的 SGE 和 MUM
顯然,Google相信機器產生的內容可以回答使用者的查詢。自 2021 年 5 月發布 MUM(多任務統一模型)以來,Google就已經暗示了這一點。
MUM 著手解決的一項挑戰是基於人們對複雜任務平均發出八次查詢的資料。
在初始查詢中,搜尋者將了解一些附加信息,提示相關搜尋並顯示新網頁來回答這些查詢。
谷歌提出:如果他們可以接受初始查詢,預測用戶後續問題,並使用他們的索引知識產生完整的答案,會怎麼樣?
如果它有效,雖然這種方法對使用者來說可能很棒,但它本質上消除了SEO 賴以在 SERP 中立足的許多「長尾」或零量關鍵字策略。
假設谷歌可以識別適合人工智慧生成答案的查詢,那麼許多問題都可以被視為「解決」。
這就提出了一個問題…
- 當 Google 可以將使用者保留在其搜尋生態系統中並自行產生答案時,為什麼要向搜尋者展示您的網頁以及預先產生的答案呢?
谷歌有經濟誘因將用戶保留在其生態系統中。我們已經看到了實現這一目標的各種方法,從特色片段到讓人們在 SERP 中搜尋航班。
假設 Google 認為您產生的文字無法提供超出其已經提供的價值。在這種情況下,這只是搜尋引擎的成本與效益的問題。
從長遠來看,他們能否透過吸收生成費用並讓用戶等待答案而不是快速而廉價地將用戶發送到他們知道已經存在的頁面來產生更多收入?
檢測 AI 內容
隨著 ChatGPT 使用量的爆炸式增長,出現了數十種“人工智慧內容檢測器”,它們允許您輸入文字內容並輸出百分比分數 – 這就是問題所在。
儘管不同的偵測器標記這個百分比分數的方式存在一些差異,但它們幾乎總是給出相同的輸出:整個提供的文字是人工智慧產生的百分比確定性。
當百分比被標記為「75% AI / 25% Human」時,這會導致混亂。
許多人會誤解這意味著“該文本 75% 由人工智能編寫,25% 由人類編寫”,而它的意思是“我 75% 確定該文本 100% 是由人工智能編寫的。”
這種誤解導致一些人就如何調整文字輸入以使其「通過」人工智慧偵測器提供建議。
例如,使用雙感嘆號 (!!) 是一種非常人性化的特徵,因此將其添加到某些 AI 生成的文本中將導致 AI 檢測器給出「99%+ 人類」分數。
這會被誤解為您「欺騙」了探測器。
但這就是探測器完美運作的一個例子,因為提供的通道不再 100% 由人工智慧產生。
不幸的是,這種能夠「欺騙」人工智慧偵測器的誤導性結論通常也與Google等搜尋引擎未偵測到人工智慧內容混淆,從而給網站所有者帶來錯誤的安全感。
Google 關於 AI 內容的政策與行動
谷歌關於人工智慧內容的聲明歷來都很模糊,這給他們在執行方面留下了迴旋餘地。
然而,今年谷歌搜尋中心發布了 更新的指南,其中明確指出:
“我們的重點是內容的質量,而不是內容的製作方式。”
甚至在此之前,Google搜尋聯絡員丹尼·沙利文(Danny Sullivan)就介入 Twitter 對話,確認他們「並沒有說人工智慧內容不好」。
谷歌列出了人工智慧如何產生有用內容的具體範例,例如體育比分、天氣預報和成績單。
很明顯,谷歌更關心的是輸出結果,而不是實現目標的手段,加倍努力“以操縱搜尋結果排名為主要目的生成內容違反了我們的垃圾郵件政策。”
谷歌在打擊 SERP 操縱方面擁有多年經驗,聲稱其係統的進步(例如SpamBrain)已使99% 的搜索“無垃圾內容”,其中包括 UGC 垃圾內容、抓取、偽裝和所有各種形式的內容一代。
許多人都進行了測試,看看谷歌對人工智慧內容有何反應,以及他們在品質方面的界限。
在 ChatGPT 推出之前,我創建了一個包含 10,000 頁內容的網站,主要由無監督的 GPT3 模型生成,回答人們也提出的有關視頻遊戲的問題。
透過最少的鏈接,該網站很快就被索引並穩步增長,每月提供數千名訪客。
在 2022 年的兩次 Google 系統更新(有用內容更新和後來的垃圾內容更新)期間,Google 突然幾乎完全壓制了該網站。
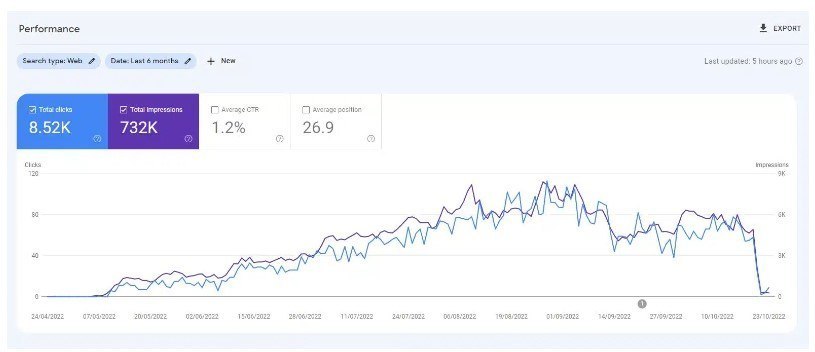
從這樣的實驗中得出「人工智慧內容不起作用」的結論是錯誤的。
然而,這向我表明,在那個特定時間,Google:
- 沒有將不受監督的 GPT-3 內容歸類為「品質」。
- 可以透過大量其他訊號檢測並消除此類結果。
為了得到最終的答案,你需要一個更好的問題
根據 Google 的指導方針、我們對搜尋系統的了解、SEO 實驗和常識,“搜尋引擎可以檢測 AI 內容嗎?”可能是錯誤的問題。
充其量,這只是一個很短期的觀點。
在大多數主題中,法學碩士很難在事實準確性和滿足 Google EEAT標準方面始終如一地產生「高品質」內容,儘管他們可以即時存取網路以獲取訓練資料之外的資訊。
人工智慧在為以前內容稀缺的查詢產生答案方面取得了重大進展。但隨著Google與 SGE 一起實現更崇高的長期目標,這種趨勢可能會消退。
預計重點將回歸到較長形式的專家內容,谷歌的知識系統將提供答案來滿足許多長尾查詢,而不是引導用戶訪問眾多小網站。
