什麼是語意搜尋:深入探討基於實體的搜尋

什麼是語意搜尋:深入探討基於實體的搜尋
語意 = 意義理論,但大多數語意搜尋的定義都專注於意圖。 「意義」與「意圖」不同。了解更多。
自2013年起,Google逐步發展成為100%語意的搜尋引擎。
語意搜尋到底是什麼?當你使用 Google 搜尋該問題的答案時,你可以找到很多解釋 – 但其中大多數都不精確並且會造成誤解。
本文將幫助您全面了解什麼是語意搜尋。
Google成為語意搜尋引擎的道路
Google開發語意搜尋引擎的努力可以追溯到 1999 年(已故 Bill Slawski 的這篇文章中提到)。隨著 2012 年知識圖譜的推出以及 2013 年排名演算法的根本性變化(俗稱蜂鳥),這一點變得更加具體。
所有其他主要創新,如RankBrain、EAT、BERT和MUM都直接或間接地支援成為完全語義搜尋引擎的目標。
透過將自然語言處理 (NLP) 引入搜索,Google正以指數級的速度朝著這一目標邁進。
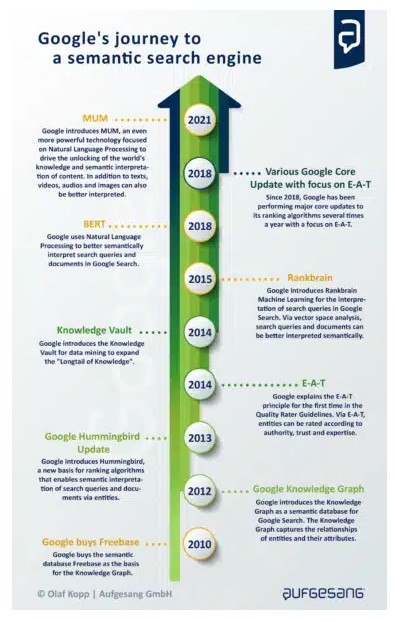
蜂鳥:「不是字串,而是事物」=實體
蜂鳥是Google向語意搜尋引擎進化的起始訊號。
這是Google有史以來最大的搜尋查詢處理和排名變革,早在 2013 年就影響了超過 90% 的搜尋。蜂鳥從根本上取代了許多現有的排名演算法。
透過蜂鳥,Google能夠立即將知識圖譜中記錄的實體納入查詢處理、排名和 SERP 的輸出。
實體描述具體或抽象物件的本質或身分。實體具有唯一的可識別性,因此具有唯一的意義。
基本上,可以區分命名實體和抽象概念。
- 命名實體是現實世界的對象,例如人、地點、組織、產品和事件。
- 抽象概念的本質是物理性的、心理的或社會的,例如距離、數量、情緒、人權、和平等。
在 Hummingbird 出現之前,Google 主要透過關鍵字文件配對來進行排名,無法識別搜尋查詢或內容的含義。
什麼是語意搜尋引擎?
語義搜尋引擎會考慮搜尋查詢和內容的語義上下文,以便更好地理解含義。語意搜尋引擎也會考慮實體之間的關係來傳回搜尋結果。
相較之下,純粹基於關鍵字的搜尋系統僅在關鍵字文字匹配的基礎上運作。
什麼是語義搜尋?
語義搜尋的許多定義都側重於將搜尋意圖解釋為其本質。但首先,語意搜尋是根據出現的實體來識別搜尋查詢和內容的意思。
語意學 = 意義理論。
但「意義」與「意圖」不同。搜尋意圖描述了用戶對搜尋結果的期望。意義是別的東西。
識別含義可以幫助識別搜尋意圖,但更多的是語義搜尋的額外好處。
知識圖譜在Google語義搜尋中的作用
基於實體的排名也需要基於實體的索引。知識圖譜是 Google 的實體索引,它考慮了實體之間的關係。
經典索引以表格形式組織,因此不允許資料集之間的映射關係。
知識圖譜是一個語義資料庫,其中的資訊以這樣的方式構建,即從資訊中創建知識。在這裡,實體(節點)透過邊相互關聯,具有屬性和其他訊息,並放置在主題上下文或本體中。
實體是語意資料庫(例如 Google 的知識圖譜)中的核心組織元素。
除了實體之間的關係之外,Google還使用資料探勘來收集實體的屬性和其他信息,並圍繞實體進行組織。
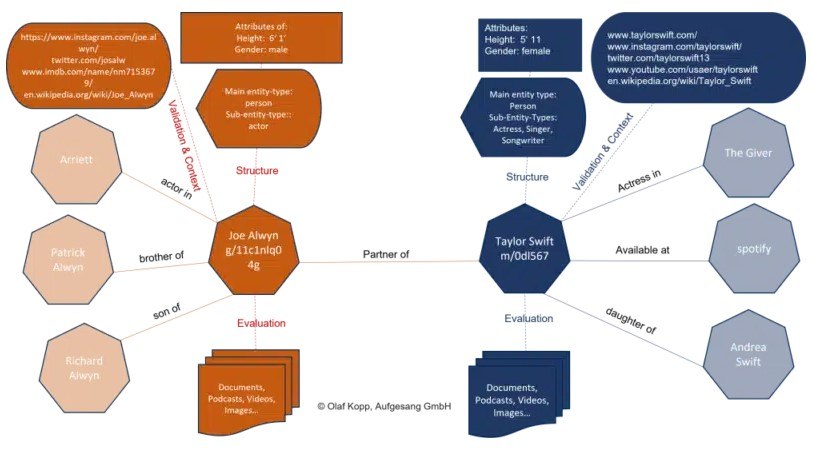
您可以了解 Google 在搜尋某個實體時會考慮哪些來源和資訊。
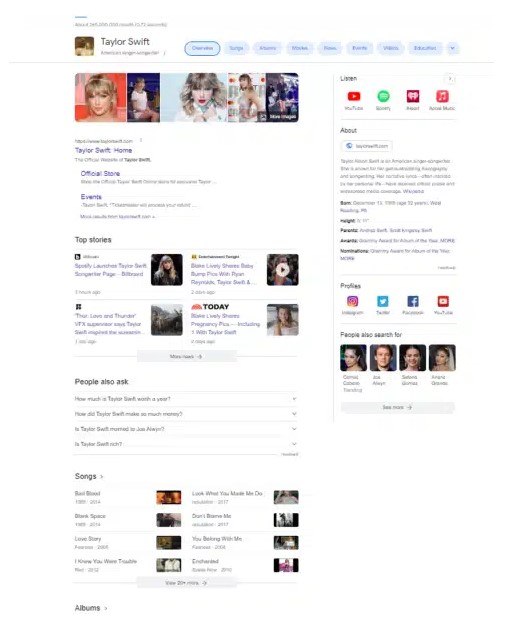
首選的來源、屬性和資訊會根據實體類型而有所不同。人物實體的來源與事件實體或組織實體不同。這會影響知識面板中顯示的資訊。
基於實體的索引結構允許回答搜尋問題中未提及的主題或實體的問題。
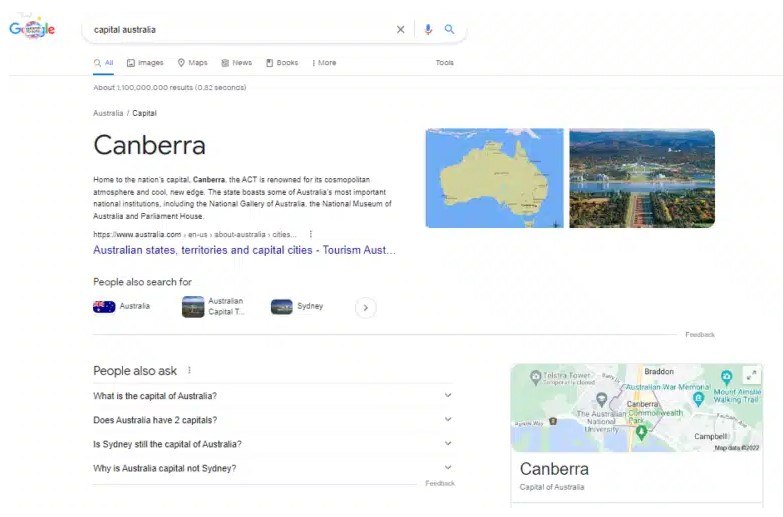
「坎培拉」是與「澳洲」相關的實體
在這個例子中,「澳洲」和「坎培拉」是實體,而「首都」的值描述了關係的性質。基於關鍵字的搜尋引擎不可能回傳這個答案。
知識圖譜的基礎有三個層次:
- 實體目錄:所有隨時間推移而被識別的實體都儲存在這裡。
- 知識庫:實體被匯集到知識庫中,包含來自各種來源的資訊或屬性。這主要是關於合併和儲存描述並以實體類型的形式建立語義類別或群組。 Google 透過知識庫產生數據,並從非結構化來源進行資料探勘。
- 知識圖譜:實體與屬性相鏈接,實體之間建立關係。
Google 可以使用各種來源來識別實體及其相關資訊。
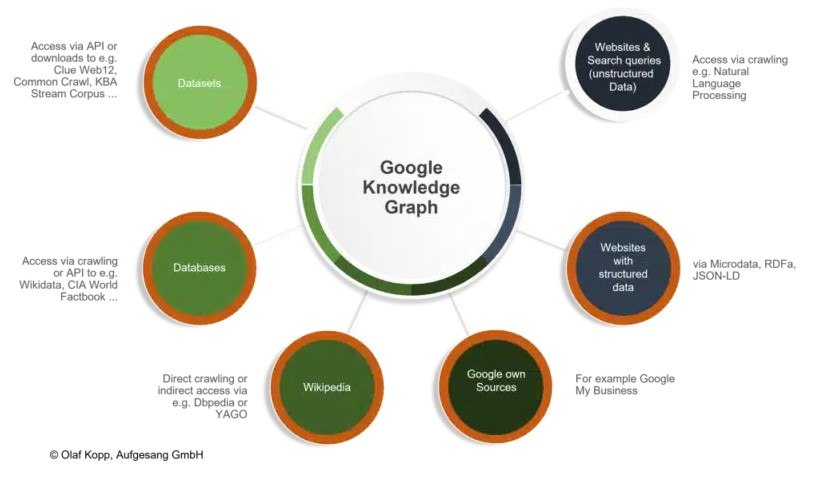
知識庫中所捕捉的實體並非都包含在知識圖譜中。以下標準可能會影響知識圖譜的納入程度:
- 可持續的社會意義。
- Google 索引中該實體的搜尋命中次數足夠。
- 持久的公眾認知。
- 公認的字典或百科全書或專業參考書中的條目。
可以假設,Google在知識庫(如知識庫)中記錄了比知識圖譜中多得多的長尾實體,並將其用於語義搜尋。
透過抓取開放的互聯網並透過自然語言處理,Google能夠獨立於結構化和半結構化資料庫進行可擴展的實體和資料探勘。這為知識庫提供了越來越多的信息,包括長尾實體的資訊。您可以在此處找到有關此內容的更多資訊。
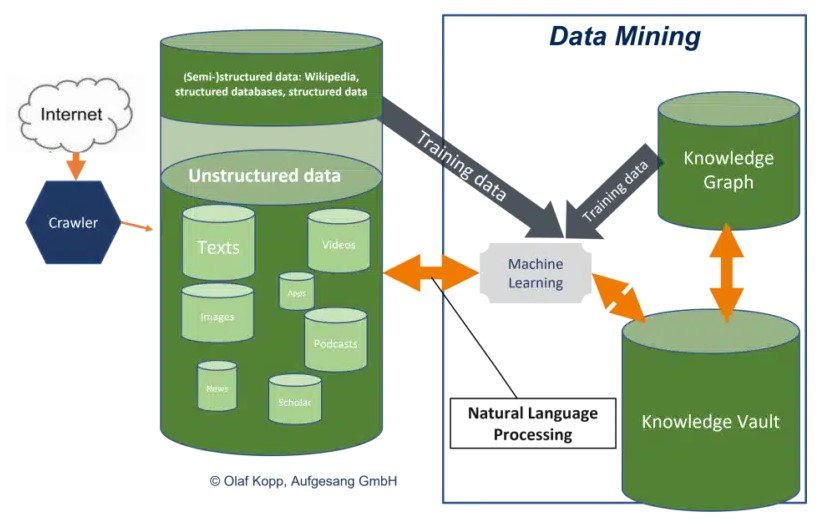
Google 作為語意搜尋引擎如何運作?
Google 在以下領域使用語意搜尋:
- 了解搜尋查詢處理中的搜尋查詢或實體。
- 了解有關實體的內容以進行排名。
- 了解資料探勘的內容和實體。
- 對實體進行上下文分類,以便稍後進行 EAT 評估。
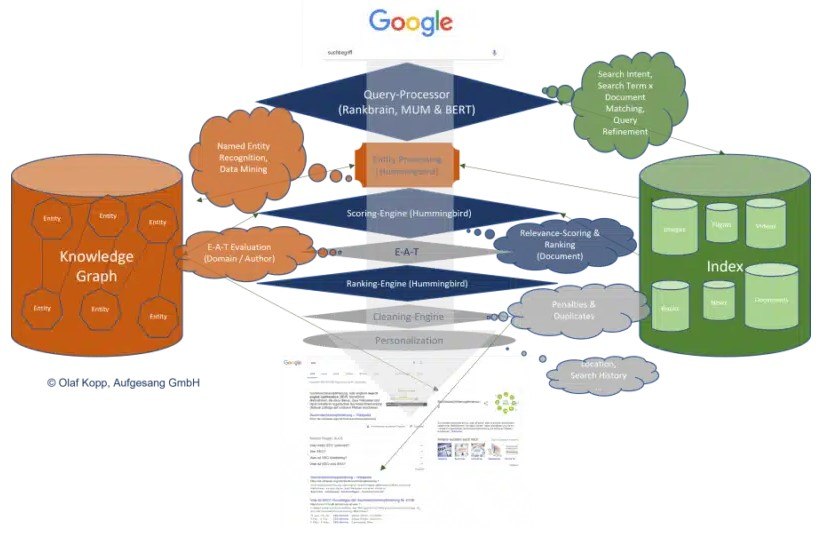
谷歌搜尋現在基於搜尋查詢處理器來解釋搜尋查詢並從與搜尋查詢相關的文件中彙編語料庫。這就是 BERT、MUM 和 RankBrain 可以發揮作用的地方。
在搜尋查詢處理中,將搜尋字詞與語意資料庫中記錄的實體進行比較,並在必要時進行細化或重寫。
接下來一步,確定搜尋意圖,確定適當的X內容語料庫。
Google 使用經典搜尋索引以及以知識圖譜形式存在的語意資料庫。這兩個資料庫之間很可能透過介面進行交換。
有一個基於蜂鳥核心演算法、由不同演算法組成的評分引擎。它負責評估內容,然後根據評分進行排序。評分是關於內容與搜尋查詢或搜尋意圖的相關性。
由於 Google 除了評估相關性之外,還希望評估內容的質量,因此還必須根據 EAT 標準進行評估。您可以從Google 評估 EAT 的 14 種方式中了解這些標準。
對於此 EAT 評估,Google 必須評估網域、發布者和/或作者的專業性、權威性和可信度。語義實體資料庫可以作為實現這一點的基礎。
然後,透過清理引擎清除搜尋結果中的重複項,並考慮所有懲罰。
這對語義 SEO 意味著什麼?
當談到語義 SEO 時,我閱讀了大量有關結構化資料、內容的語義優化和語義主題世界的結構的文章。
是的,向 Google 展示您的內容完全涵蓋了某些主題並因此展現了專業知識,這是有意義的。
一些專利涉及文件內部知識圖譜與 Google 知識圖譜的比較。這裡的理論是,文本中使用的實體與 Google 語義資料庫中主要實體的關係結構之間的高度對應性會帶來更好的排名。
這聽起來很合乎邏輯。但說實話,最終基於關鍵字的最佳化與基於實體的內容優化並沒有顯著差異。
主題世界的結構也是有意義的,儘管必須指出,在文章排名時,應考慮以下幾點:
- 一個主題在多大程度上可以細分為各個子主題?
- 每個子主題是否製作單獨的內容?
- 是否只創造了整體內容資產?
還有結構化資料…
是的,結構化資料可以幫助Google理解語義關係,但僅限於他們不再需要它之前。而那很快就會實現。
在我看來,Google在機器學習方面非常出色,他們正在使用結構化資料來更快地訓練演算法。
讓我們以社群媒體資料的標記為例。從Google推薦使用它到他們宣布可以自動查看沒有結構化資料的社交資料,只花了大約一年的時間。
谷歌不再需要結構化資料只是時間問題。
結構化資料也不是評估的良好基礎。你要么擁有它們,要么沒有。
您可以將所有這些歸結為語義 SEO。然而,我常常忽略出版商和作者等實體的全球視野。在這裡,頁外訊號比頁內訊號發揮更大的作用。基於權威和可信實體之間的關係,Google 希望根據 EAT 確定哪些領域和作者是某個主題的最佳品質來源。
- 誰和誰有關係?
- 誰推薦誰?
- 誰和誰一起出去玩?
來自 Google 的連結和共現可用作權威實體之間接近度的因素。我所說的語義 SEO 也意味著對其進行最佳化。
當我們討論共現問題時,您還應該考慮 NLP 在優化內容時如何運作。 Google 使用 NLP 來識別實體及其上下文。這是透過由名詞和動詞組成的語法句子結構、三元組和元組來實現的。
這就是為什麼我們在語意SEO中也應該注意語法簡單的句子結構。使用沒有人稱代名詞和嵌套的短句子。這就是我們在可讀性和搜尋引擎方面為用戶提供服務的方式。
語意搜尋的未來:何時才能實現100%基於實體的Google搜尋?
我認為未來經典的 Google 搜尋索引和知識圖譜之間將透過介面進行越來越多的交換。
知識圖譜中記錄的實體越多,它們對 SERP 的影響就越大。然而,谷歌仍然面臨著協調完整性和準確性的重大挑戰。
對於蜂鳥的實際評分來說,文件層級實體並不扮演主要角色。相反,它們是在搜尋索引端建立非加權文檔語料庫的重要組織元素。
文件的實際評分是由 Hummingbird 根據經典資訊檢索規則完成的。然而,在領域級別,我看到實體對排名的影響要高得多。輸入EAT。
在接下來的幾年裡,我們很可能會看到實體在Google搜尋中的影響力日益增強。基於實體的搜尋的新出現清楚地表明了谷歌如何逐步圍繞實體組織資訊和內容的索引。這顯示了 MUM 等創新在多大程度上遵循了語義搜尋的概念。
