診斷常見 JavaScript SEO 問題的指南

診斷常見 JavaScript SEO 問題的指南
了解如何發現 JavaScript 網站中的 SEO 問題以及在渲染時需要了解的內容。
說實話,JavaScript和SEO並不總是能很好地協同工作。對於一些 SEO 來說,這個主題可能感覺像是被籠罩在複雜的面紗之中。
好吧,好消息:當你剝去層層外衣時,許多基於 JavaScript 的 SEO 問題都會回歸到搜尋引擎爬蟲與 JavaScript 互動的基本原理。
因此,如果您了解這些基礎知識,您就可以深入研究問題,了解其影響,並與開發人員合作解決重要問題。
在本文中,我們將協助診斷基於 JS 框架建立網站時的一些常見問題。此外,我們還將分解每個技術 SEO 在渲染方面所需的基礎知識。
渲染簡介
在我們討論更具體的問題之前,讓我們先討論一下整體情況。
搜尋引擎為了理解由 JavaScript 驅動的內容,必須抓取並呈現該頁面。
問題是,搜尋引擎只有這麼多資源可用,所以他們必須選擇何時使用它們。即使爬蟲將頁面傳送到渲染佇列,也不一定會渲染該頁面。
如果它選擇不呈現頁面,或無法正確呈現內容,則可能會出現問題。
這取決於前端如何在初始伺服器回應中提供 HTML。
當在瀏覽器中建立 URL 時,React、Vue 或 Gatsby 等前端將產生該頁面的 HTML。在傳送 URL 以等待渲染之前,爬蟲程式會檢查伺服器是否已提供該 HTML(「預先渲染」 HTML),以便查看結果內容。
是否有預先渲染的 HTML 取決於前端的配置方式。它將透過伺服器或客戶端瀏覽器產生 HTML。
伺服器端渲染
名字已說明了一切。在 SSR 設定中,爬蟲會獲得完全呈現的 HTML 頁面,而無需額外的 JS 執行和呈現。
因此,即使頁面未呈現,搜尋引擎仍然可以抓取任何 HTML、將頁面情境化(元資料、副本、圖像),並了解其與其他頁面的關係(麵包屑、規範 URL、內部連結)。
客戶端渲染
在 CSR 中,HTML 與所有 JavaScript 元件一起在瀏覽器中產生。在 HTML 可供抓取之前,JavaScript 需要渲染。
如果渲染服務選擇不渲染發送到佇列的頁面,則副本、內部 URL、圖像連結甚至元資料對於爬蟲來說仍然不可用。
因此,搜尋引擎幾乎沒有任何上下文來理解 URL 與搜尋查詢的相關性。
注意:初始 HTML 回應中可能會混合提供 HTML,以及需要 JS 執行才能呈現(顯示)的 HTML。這取決於幾個因素,其中最常見的包括框架、各個網站元件的建置方式以及伺服器配置。
JavaScript SEO 工具包
當然,有一些工具可以幫助識別與 JavaScript 相關的 SEO 問題。
您可以使用瀏覽器工具和 Google Search Console 進行大量調查。以下是組成可靠工具包的候選清單:
- 查看原始程式碼:右鍵單擊頁面,然後按一下「查看原始程式碼」以查看頁面的預渲染 HTML(初始伺服器回應)。
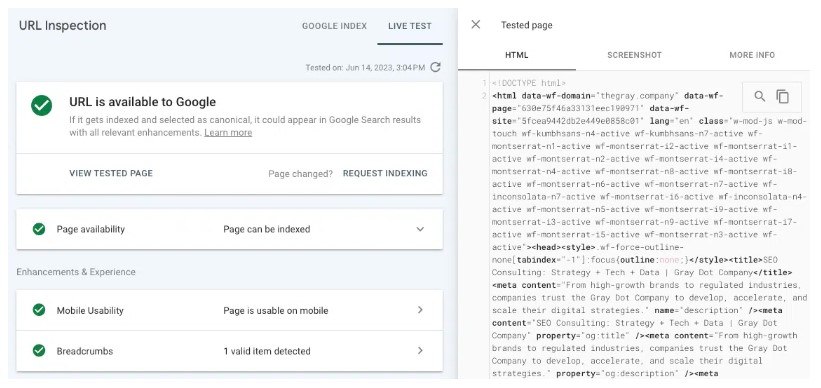
- 測試即時 URL(URL 檢查):在 Google Search Console 的 URL 檢查標籤中查看呈現頁面的螢幕截圖、HTML 和其他重要詳細資訊。 (透過將「檢視原始碼」中的預先渲染 HTML 與在 GSC 中測試即時 URL 所渲染的 HTML 進行比較,可以發現許多渲染問題。)
- Chrome 開發者工具:右鍵點擊頁面並選擇「檢查」以開啟用於查看 JavaScript 錯誤等的工具。
- Wappalyzer:透過安裝這個免費的 Chrome 擴充功能,查看任何網站所建立的堆疊並尋求特定於框架的見解。
常見的 JavaScript SEO 問題
問題 1:預渲染 HTML 一般不可用
除了前面提到的對爬行和脈絡化的負面影響之外,還有搜尋引擎呈現頁面所需的時間和資源問題。
如果爬蟲選擇讓某個 URL 經過渲染過程,那麼它最終會進入渲染佇列。發生這種情況的原因是,爬蟲程式可能會感知到預先渲染和渲染後的 HTML 結構之間的差異。 (如果沒有預先渲染的 HTML,這很有意義!)
無法保證 URL 等待 Web 渲染服務的時間長度。促使 WRS 及時呈現的最佳方法是確保現場有關鍵權威訊號來說明 URL 的重要性(例如,連結在頂部導航中、有許多內部連結、引用為規範)。這有點複雜,因為權威訊號也需要被抓取。
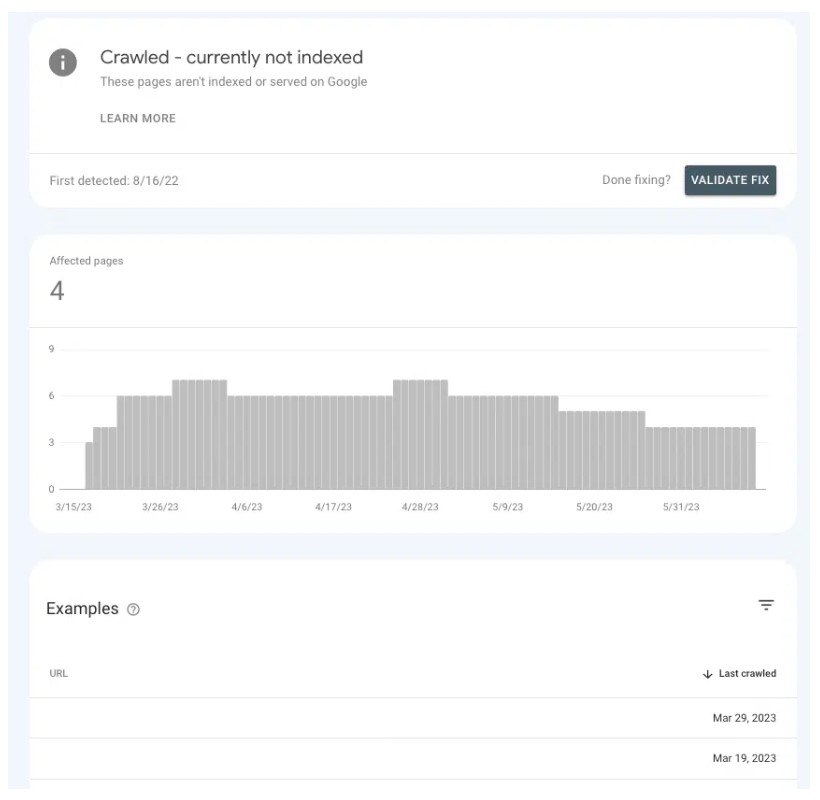
在 Google Search Console 中,您可以了解您是否向關鍵頁面發送了正確的權威訊號或導致它們處於不確定狀態。
前往頁面 > 頁面索引 > 已抓取 – 目前未編入索引,然後尋找清單中是否存在優先頁面。
如果他們在等候室,那是因為Google無法確定他們是否重要到值得投入資源。
常見原因
預設設定
大多數流行的前端都“開箱即用”,設置為客戶端渲染,因此很有可能預設是罪魁禍首。
如果你想知道為什麼大多數前端預設使用 CSR,那是因為它具有效能優勢。開發人員並不總是喜歡 SSR,因為它會限制加速網站和實現某些互動元素(例如頁面之間的獨特轉換)的可能性。
單頁應用程式
如果網站是單頁應用程序,則它完全用 JavaScript 包裝並在瀏覽器中生成頁面的所有元件(即所有內容)在客戶端呈現,並且無需重新加載即可提供新頁面。
這會產生一些負面影響,其中最重要的或許是頁面可能無法被發現。
這並不是說不可能以更有利於 SEO 的方式設定 SPA。但很有可能,要實現這一目標需要進行大量的開發工作。
問題 2:某些頁面內容無法被爬蟲訪問
讓搜尋引擎呈現 URL 非常棒,但前提是所有元素都可以抓取。如果它正在呈現頁面,但頁面的某些部分無法訪問,該怎麼辦?
例如,SEO 進行內部連結分析,發現多個頁面上連結的 URL 幾乎沒有內部連結。
如果該連結沒有顯示在「測試即時 URL」工具呈現的 HTML 中,那麼它很可能是在 Google 無法存取的 JavaScript 資源中提供的。
為了縮小問題範圍,最好在各個 URL 中尋找缺失頁面內容或內部連結在頁面上的共同點。
例如,如果它是出現在每個產品頁面同一部分中的常見問題解答鏈接,那麼這將在很大程度上幫助開發人員縮小修復範圍。
常見原因
JavaScript 錯誤
我們先來聲明一下。您遇到的大多數 JavaScript 錯誤與 SEO 無關。
因此,如果你開始尋找錯誤,將一長串清單交給開發人員,並以「這些錯誤是什麼?」開始對話,他們可能不會很好地接受它。
透過談論問題來尋找「為什麼」的方法,這樣他們就可以成為 JavaScript 專家(因為他們就是!)。
話雖如此,語法錯誤可能會導致頁面的其餘部分無法解析(例如“渲染阻止”)。當發生這種情況時,渲染器無法分解單一 HTML 元素、建構 DOM 中的內容或理解關係。
一般來說,這些類型的錯誤是可識別的,因為它們在瀏覽器視圖中也會產生某種影響。
除了視覺確認之外,還可以透過右鍵單擊頁面、選擇「檢查」並導航至「控制台」標籤來查看 JavaScript 錯誤。
內容需要用戶互動
關於渲染,需要記住的最重要的事情之一是,Google 無法渲染任何需要使用者與頁面互動的內容。或者,更簡單地說,它無法「點擊」東西。
這有什麼關係?想想我們的老朋友、可信賴的朋友——手風琴下拉菜單,有多少網站使用它來組織產品詳細資訊和常見問題解答等內容。
根據手風琴的編碼方式,如果直到 JS 執行後下拉式選單才填滿內容,Google 可能無法呈現下拉式選單中的內容。
要檢查,您可以「檢查」一個頁面,看看「隱藏」內容(點擊手風琴時顯示的內容)是否在 HTML 中。
如果不是,則表示 Googlebot 和其他抓取工具在頁面的呈現版本中看不到該內容。
問題 3:網站的部分內容未被抓取
如果 Google 抓取了您的網頁並將其傳送到佇列,它可能會或可能不會呈現您的網頁。如果它不抓取該頁面,那麼這個機會就消失了。
要了解 Google 是否正在抓取網頁,抓取統計資料報告會派上用場:設定 > 抓取統計資料。
選擇抓取請求:確定(200)可查看過去三個月內所有200個狀態頁面的抓取實例。然後,使用過濾來搜尋單一 URL 或整個目錄。
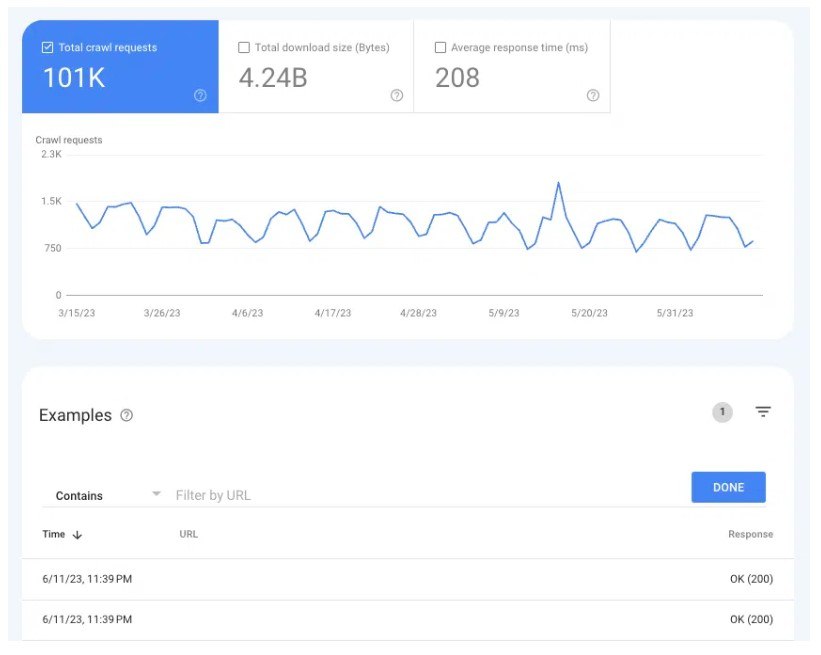
如果 URL 沒有出現在抓取日誌中,則 Google 很可能無法發現並抓取這些網頁(或者它們不是 200 個網頁,這是一個完全不同的問題)。
常見原因
內部連結不可抓取
連結是爬蟲程序到達新頁面所遵循的路標。這就是孤立頁面造成如此大問題的原因之一。
如果您的網站連結良好,但在網站審核中看到孤立頁面彈出,很有可能是因為預先渲染的 HTML 中沒有這些連結。
一個簡單的檢查方法是存取連結到所報告的孤立頁面的 URL。右鍵單擊該頁面,然後按一下“查看原始程式碼”。
然後,使用 CMD + f 搜尋孤立頁面的 URL。如果它沒有出現在預先渲染的 HTML 中,但在瀏覽器中渲染時出現在頁面上,請跳至第四個問題。
XML網站地圖未更新
XML 網站地圖對於幫助 Google 發現新頁面以及了解在抓取中優先考慮哪些 URL 至關重要。
如果沒有 XML 網站地圖,則只能透過點擊連結來發現頁面。
因此,對於沒有預先渲染 HTML 的網站,過時或缺少的網站地圖意味著等待 Google 渲染頁面、追蹤內部連結到其他頁面、對其進行排隊、渲染它們、追蹤它們的連結等等。
根據您使用的前端,您可能可以存取可建立動態 XML 網站地圖的插件。
它們通常需要定制,因此 SEO 人員必須認真記錄不應出現在網站地圖中的任何 URL 及其原因邏輯。
透過您最喜歡的 SEO 工具運行網站地圖,這應該相對容易驗證。
問題 4:缺少內部連結
爬蟲無法獲得內部連結不僅是一個潛在的發現問題,而且還是一個公平問題。由於連結將 SEO 權益從參考 URL 傳遞到目標 URL,因此它們是提升頁面和網域權威的重要因素。
主頁上的連結就是一個很好的例子。它通常是網站上最權威的頁面,因此從主頁到另一個頁面的連結具有很大的影響力。
如果這些連結無法抓取,那麼就像一把壞掉的光劍一樣。您最強大的工具之一變得毫無用處(雙關語)。
常見原因
到達連結需要用戶交互
我們之前使用的手風琴範例只是內容隱藏在使用者互動背後的一個例子。另一個可能具有廣泛影響的是無限滾動分頁——特別是對於擁有大量產品目錄的電子商務網站。
在無限滾動設定中,產品清單(類別)頁面上的無數產品都不會加載,除非使用者滾動到某個點之外(延遲加載)或點擊「顯示更多」按鈕。
因此,即使 JavaScript 被呈現,爬蟲也無法存取尚未載入的產品的內部連結。然而,由於頁面效能不佳,將所有這些產品載入到一個頁面上會對使用者體驗產生負面影響。
這就是為什麼 SEO 通常更喜歡真正的分頁,其中每個結果頁面都有一個獨特的、可抓取的 URL。
雖然網站可以透過多種方式優化延遲載入並將所有產品新增至預先渲染的 HTML 中,但這會導致渲染的 HTML 與預先渲染的 HTML 之間存在差異。
實際上,這產生了向渲染隊列發送更多頁面的理由,並使爬蟲程序比其需要的更努力地工作 – 我們知道這對 SEO 來說並不好。
至少,請遵循 Google 關於優化無限滾動的建議。
連結編碼不正確
當 Google 抓取某個網站或在佇列中呈現某個 URL 時,它會下載該頁面的無狀態版本。這就是為什麼使用正確的 href 標籤和錨點(您最常看到的連結結構)如此重要的重要原因。爬蟲無法遵循諸如 router、span 或 onClick 之類的連結格式。
可以關注:
- <a href=”https://example.com”>
- <a href=”/相對/路徑/檔案”>
無法關注:
- <a routerLink=”some/path”>
- <span href=”https://example.com”>
- <a onclick=”goto(‘https://example.com’)”>
對於開發人員的目的而言,這些都是編碼連結的有效方法。 SEO 意義是額外的背景層,這不是他們的工作,而是 SEO 的工作。
優秀 SEO 工作的很大一部分是透過文件向開發人員提供相關背景資訊。
問題 5:缺少元數據
在 HTML 頁面中,標題、描述、規範 URL 和元 robots 標籤等元資料都嵌套在 head 中。
顯而易見,缺少元資料對 SEO 有害,但對 SPA 的損害更大。自引用規範 URL 之類的元素對於提高 JS 頁面成功通過渲染佇列的機會至關重要。
在預先渲染 HTML 中應存在的所有元素中,head 對於索引來說是最重要的。
幸運的是,這個問題很容易發現,因為無論網站使用哪種 SEO 工具進行衛生報告,缺少元資料都會引發大量錯誤。然後,您可以透過在原始程式碼中找到頭部來確認。
常見原因
缺乏或配置錯誤的元資料載體
在 JS 框架中,插件會建立頭部並將元資料插入頭部。 (最受歡迎的例子是 React Helmet。)即使插件已經安裝,通常也需要正確配置。
再次強調,在這個領域,所有 SEO 所能做的就是將問題提交給開發人員,解釋原因,並密切合作以達到有據可查的驗收標準。
問題 6:資源未被抓取
腳本檔案和圖像是渲染過程中必不可少的組成部分。
由於它們也有自己的 URL,因此可爬行性法則也適用於它們。如果檔案被阻止抓取,Google 將無法解析並呈現該頁面。
若要查看 URL 是否已抓取,您可以查看 GSC Crawl Stats 中的過去的請求。
- 圖片:前往「設定」>「抓取統計」>「抓取請求」:圖片
- JavaScript:前往“設定”>“抓取統計”>“抓取請求:圖片”
常見原因
robots.txt 封鎖的目錄
腳本和圖像 URL 通常嵌套在各自專用的子網域或子資料夾中,因此 robots.txt 中的禁止表達式將阻止抓取。
一些 SEO 工具會告訴您是否有腳本或圖像檔案被阻止,但如果您知道圖像和腳本檔案嵌套的位置,則很容易發現問題。您可以在 robots.txt 中找到這些 URL 結構。
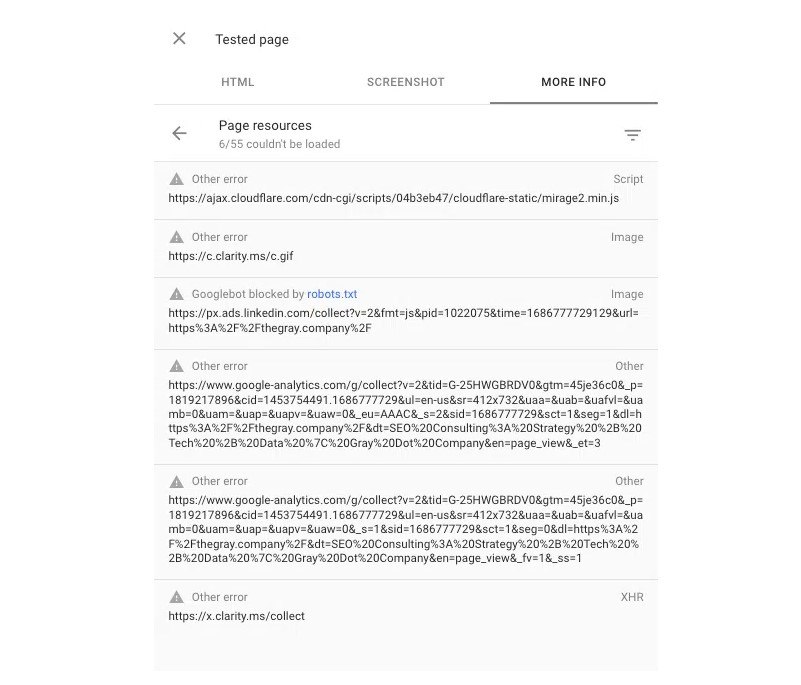
您也可以使用 Google Search Console 中的 URL 檢查工具查看呈現頁面時被封鎖的任何腳本。 「測試即時 URL」然後前往查看測試頁面 > 更多資訊 > 頁面資源。
您可以在此處看到渲染過程中載入失敗的任何腳本。如果某個檔案被 robots.txt 阻止,則會被標記為封鎖。
與 JavaScript 交朋友
是的,JavaScript 可能會帶來一些 SEO 問題。但隨著 SEO 的發展,最佳實踐正成為良好使用者體驗的代名詞。
良好的使用者體驗通常依賴 JavaScript。因此,雖然 SEO 的工作不是編寫 JavaScript,但我們確實需要了解搜尋引擎如何與之互動、呈現和使用它。
透過對渲染過程和 JS 框架中的一些常見 SEO 問題有深入的了解,您就可以很好地識別問題並成為開發人員的強大盟友。
