網路爬蟲指南:你需要知道什麼

網路爬蟲指南:你需要知道什麼
您的網站目前正在被抓取。找出哪些機器人對您的 SEO 有幫助,哪些機器人正在損害它,以及如何控制。
了解搜尋機器人和抓取工具之間的差異對於SEO至關重要。
網站爬蟲分為兩類:
- 第一方機器人,您可以使用它來審核和優化您自己的網站。
- 第三方機器人,從外部抓取您的網站 – 有時是為了索引您的內容(如 Googlebot),有時是為了提取資料(如競爭對手的抓取工具)。
本指南分解了可以改善您網站的技術 SEO 的第一方爬蟲和第三方機器人,探討了它們的影響以及如何有效地管理它們。
第一方爬蟲:從自己的網站挖掘見解
爬蟲可以幫助您找到改進技術 SEO 的方法。
增強網站的技術基礎、架構深度和抓取效率是增加搜尋流量的長期策略。
有時,您可能會發現重大問題 – 例如 robots.txt 檔案阻止了啟動後仍處於活動狀態的暫存網站上的所有搜尋機器人。
解決此類問題可以立即改善搜尋可見性。
現在,讓我們來探索一些您可以使用的基於爬網的技術。
透過 Search Console 的 Googlebot
您不在 Google 資料中心工作,因此您無法啟動 Googlebot 來抓取您自己的網站。
但是,透過使用Google Search Console (GSC) 驗證您的網站,您可以存取 Googlebot 的資料和見解。 (按照Google 的指導在平台上進行設定。)
GSC 可免費使用並提供有價值的資訊 – 尤其是有關頁面索引的資訊。
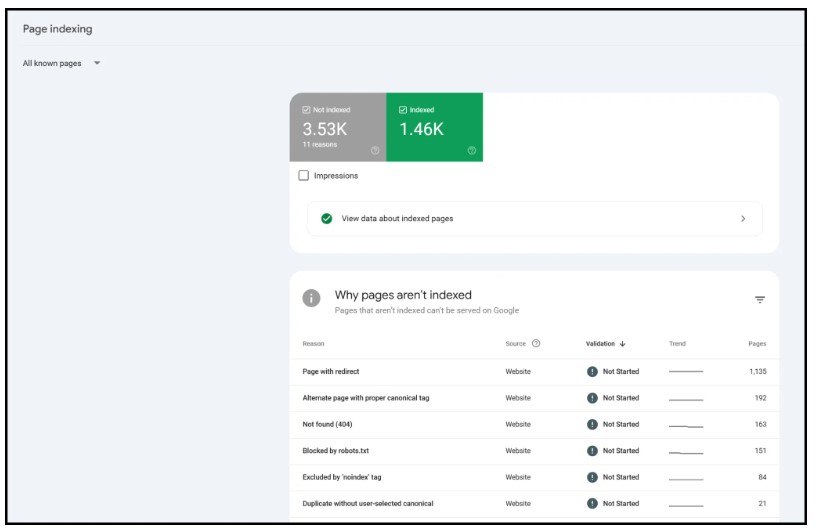
還有關於行動友善、結構化資料和核心網路生命力的數據:
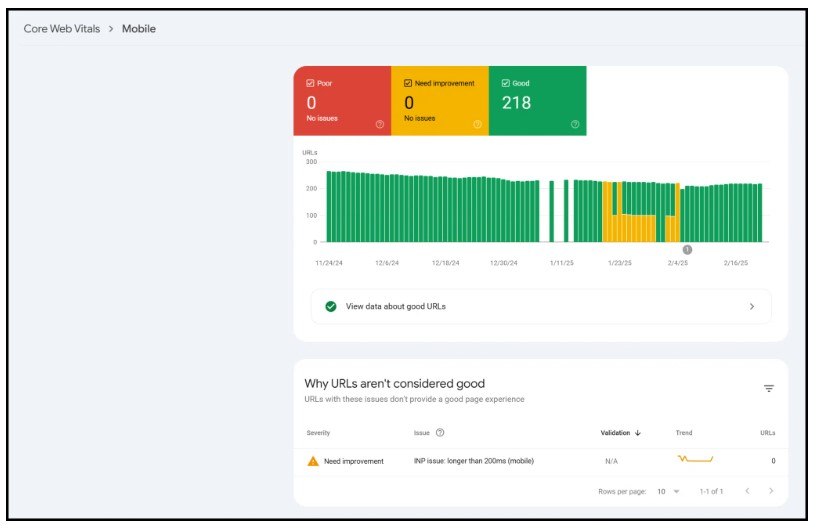
從技術上講,這是來自 Google 的第三方數據,但只有經過驗證的用戶才能在其網站上存取這些數據。
實際上,它的功能非常類似於您自己運行的抓取資料。
尖叫青蛙 SEO 蜘蛛
Screaming Frog 是一款桌面應用程序,可在您的機器上本地運行,為您的網站生成抓取資料。
他們還提供日誌文件分析器,如果您可以訪問伺服器日誌文件,它將非常有用。現在,我們將重點放在 Screaming Frog 的 SEO Spider。
每年 259 美元的價格與其他每月收費如此高昂的工具相比,它的成本效益非常高。
但是,由於它是在本地運行,所以如果您關閉計算機,抓取就會停止 – 它無法在雲端中運行。
儘管如此,它提供的數據快速、準確,對於想要深入研究技術 SEO 的人來說是理想的選擇。
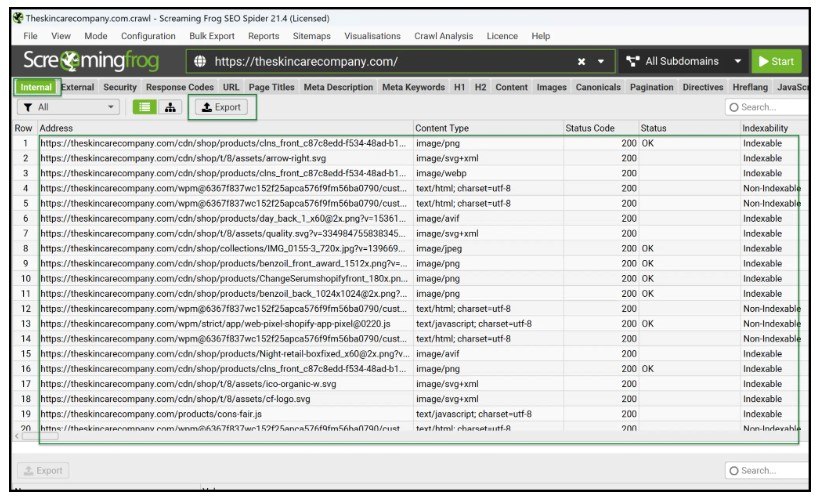
從主介面,您可以快速啟動自己的爬網。
完成後,將內部 > 所有資料匯出為 Excel 可讀格式,並輕鬆處理和透視資料以獲得更深入的見解。
Screaming Frog 還提供許多其他有用的匯出選項。
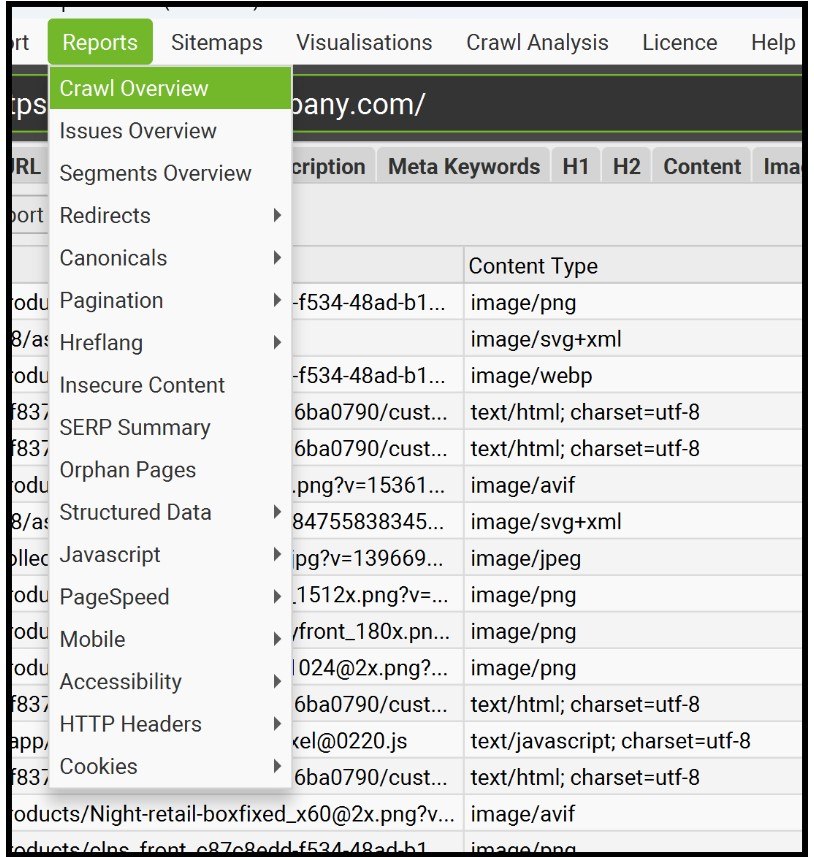
它提供內部連結、重定向(包括重定向鏈)、不安全內容(混合內容)等的報告和匯出。
缺點是它需要更多的實際管理,您需要熟悉使用 Excel 或 Google Sheets 中的資料才能最大限度地發揮其價值。
深入探討:4 種最佳技術 SEO 工具
Ahrefs 網站審核
Ahrefs 是一個綜合性的基於雲端的平台,其網站審核模組中包含一個技術 SEO 爬蟲。
要使用它,請設定一個項目,配置抓取參數並啟動抓取以產生技術 SEO 見解。
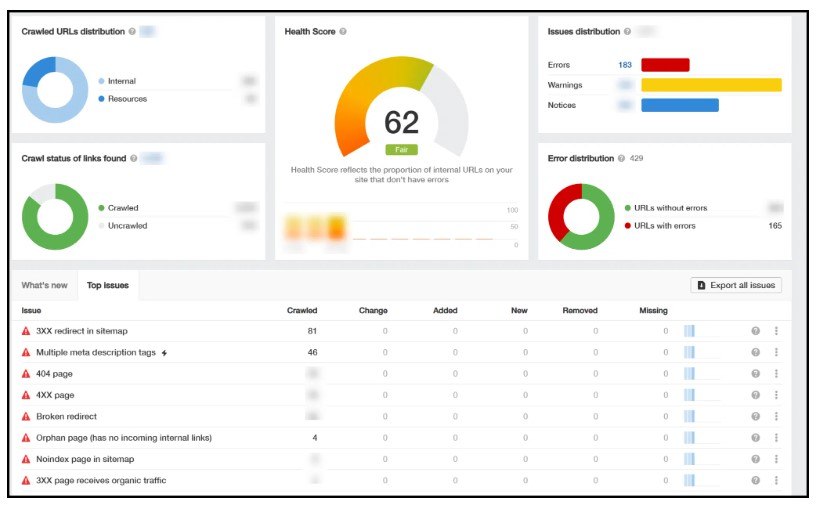
抓取完成後,您將看到一個概覽,其中包括技術 SEO 健康評級(0-100)並突出顯示關鍵問題。
您可以點擊這些問題來了解更多詳細信息,當您深入了解時,會出現一個有用的按鈕,解釋為什麼需要某些修復。
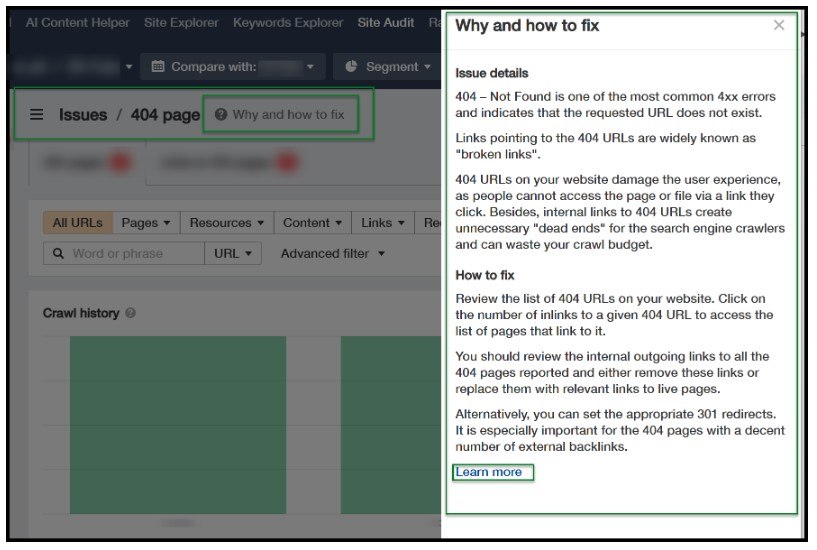
由於 Ahrefs 在雲端運行,因此您的機器的狀態不會影響抓取。即使您的 PC 或 Mac 已關閉,它仍會繼續。
與 Screaming Frog 相比,Ahrefs 提供了更多指導,使得將抓取資料轉換為可操作的 SEO 見解變得更加容易。
但其成本效益較低。如果您不需要它的附加功能(如反向連結資料和關鍵字研究),那麼它可能不值得花費。
Semrush 網站審核
接下來是 Semrush,另一個強大的基於雲端的平台,具有內建的技術 SEO 爬蟲。
與 Ahrefs 一樣,它還提供反向連結分析和關鍵字研究工具。
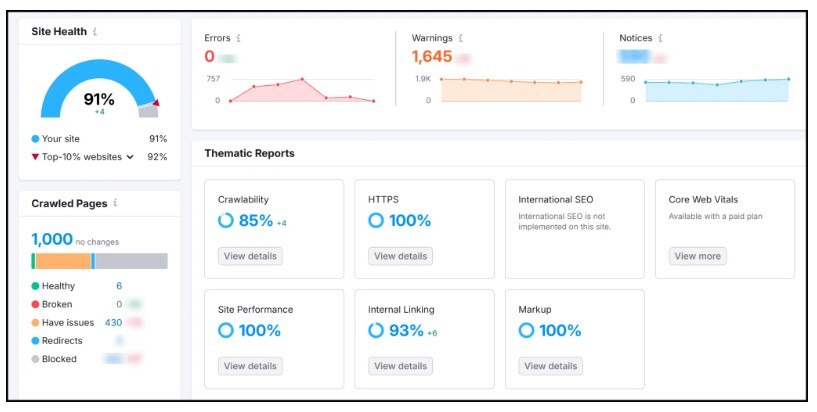
Semrush 提供技術 SEO 健康評級,隨著您修復網站問題,評級會提高。其抓取概述突出顯示了錯誤和警告。
隨著您的探索,您會發現為什麼需要修復以及如何實施修復的解釋。
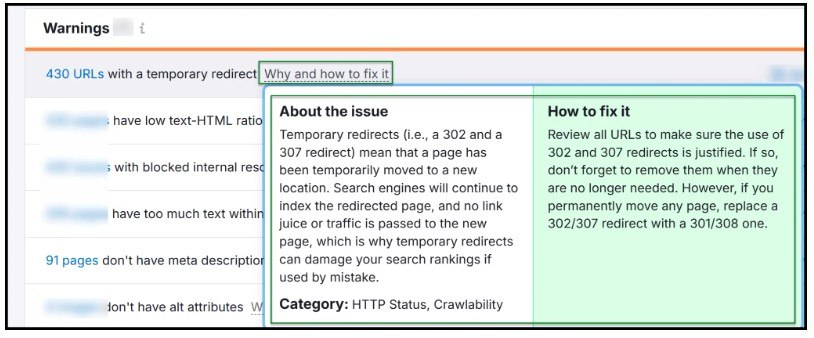
Semrush 和 Ahrefs 都具有強大的網站審核工具,可以輕鬆啟動抓取、分析資料並向開發人員提供建議。
雖然這兩個平台都比 Screaming Frog 貴,但它們擅長將抓取資料轉換為可操作的見解。
Semrush 的成本效益比 Ahrefs 略高,因此對於技術 SEO 新手來說,它是一個不錯的選擇。
第三方爬蟲:可能會造訪你網站的機器人
之前,我們討論了第三方可能由於各種原因抓取您的網站。
但是這些外部爬蟲是什麼?如何識別它們?
Googlebot
如上所述,您可以使用 Google Search Console 存取 Googlebot 對您網站的一些抓取資料。
如果 Googlebot 不抓取您的網站,那麼就沒有資料可供分析。
(您可以在此搜尋中心文件中了解有關 Google 常見抓取機器人的更多資訊。)
Google 最常見的抓取工具是:
- Googlebot 智慧型手機。
- Googlebot 桌面。
它們分別針對行動裝置和桌面使用不同的渲染引擎,但Googlebot/2.1其使用者代理字串中都包含「 」。
如果您分析伺服器日誌,則可以隔離 Googlebot 流量以查看它最常抓取您網站的哪些區域。
這有助於識別技術 SEO 問題,例如 Google 未按預期抓取的頁面。
要分析日誌文件,您可以建立電子表格來處理和轉換原始 .txt 或 .csv 檔案中的資料。如果這看起來很複雜,Screaming Frog 的日誌檔案分析器是一個有用的工具。
大多數情況下,您不應阻止 Googlebot,因為這會對 SEO 產生負面影響。
但是,如果 Googlebot 陷入高度動態的網站架構中,您可能需要透過 robots.txt 封鎖特定的 URL。謹慎使用-過度使用可能會損害你的排名。
虛假 Googlebot 流量
並非所有聲稱是 Googlebot 的流量都是合法的。
許多爬蟲程式和抓取工具允許用戶偽造用戶代理字串,這意味著他們可以偽裝成 Googlebot 來繞過抓取限制。
例如,可以設定 Screaming Frog 來模仿 Googlebot。
然而,許多網站(尤其是託管在 AWS 等大型雲端網路上的網站)可以區分真實和虛假的 Googlebot 流量。
他們透過檢查請求是否來自 Google 的官方 IP 範圍來做到這一點。
如果某個請求聲稱來自 Googlebot,但實際上來自這些範圍之外,那麼它很可能是假的。
其他搜尋引擎
除了 Googlebot 之外,其他搜尋引擎也可能會抓取您的網站。例如:
- Bingbot(微軟必應)。
- DuckDuckBot(DuckDuckGo)。
- YandexBot(Yandex,一個俄羅斯的搜尋引擎,雖然沒有很好的記錄)。
- Baiduspider(百度,中國流行的搜尋引擎)。
在您的 robots.txt 檔案中,您可以建立通配符規則來禁止所有搜尋機器人或為特定的爬蟲和目錄指定規則。
但是,請記住 robots.txt 條目是指令,而不是命令 – 這意味著它們可以被忽略。
與阻止伺服器提供資源的重定向不同,robots.txt 只是一個強烈的訊號,要求機器人不要抓取某些區域。
有些爬蟲可能會完全忽略這些指令。
尖叫青蛙的爬行機器人
Screaming Frog 通常使用類似的使用者代理來識別自己Screaming Frog SEO Spider/21.4。
始終包含“Screaming Frog SEO Spider”文本,後面跟著版本號。
然而,Screaming Frog 允許用戶自訂用戶代理字串,這意味著抓取的內容可能看起來像是來自 Googlebot、Chrome 或其他用戶代理程式。
這使得阻止尖叫青蛙爬行變得很困難。
雖然您可以阻止包含“Screaming Frog SEO Spider”的用戶代理,但操作員可以簡單地更改字串。
如果您懷疑存在未經授權的抓取,則可能需要識別並封鎖 IP 範圍。
這需要您的 Web 開發人員在伺服器端進行幹預,因為 robots.txt 無法阻止 IP – 尤其是因為 Screaming Frog 可以設定為忽略 robots.txt 指令。
但一定要小心。這可能是您自己的 SEO 團隊正在進行抓取以檢查技術 SEO 問題。
在阻止 Screaming Frog 之前,請嘗試確定流量的來源,因為它可能是內部員工收集資料。
Ahrefs 機器人
Ahrefs 有一個爬行機器人和一個用於爬行的站點審核機器人。
- 當 Ahrefs 為其自己的索引抓取網路時,您會看到來自的流量
AhrefsBot/7.0。 - 當 Ahrefs 使用者運行網站審核時,流量將來自
AhrefsSiteAudit/6.1。
根據 Ahrefs 的文檔,這兩個機器人都遵守 robots.txt 的禁止規則。
如果您不希望您的網站被抓取,您可以使用 robots.txt 阻止 Ahrefs。
或者,您的 Web 開發人員可以拒絕包含「AhrefsBot」或「AhrefsSiteAudit」的使用者代理程式的請求。
Semrush 機器人
與 Ahrefs 一樣,Semrush 使用不同的使用者代理字串運行多個爬蟲。
請務必檢查所有可用資訊以正確識別它們。
您會遇到的兩個最常見的用戶代理字串是:
- SemrushBot:Semrush 的通用網路爬蟲,用於提高其索引。
- SiteAuditBot:當 Semrush 使用者啟動網站審核時使用。
Rogerbot、Dotbot 和其他爬蟲
Moz 是另一個廣泛使用的基於雲端的 SEO 平台,它部署了 Rogerbot 來抓取網站以獲取技術見解。
Moz 也經營通用網路爬蟲 Dotbot。如果需要的話,您可以透過 robots.txt 檔案來阻止這兩者。
您可能遇到的另一個爬蟲是Majestic SEO 平台使用的MJ12Bot。通常情況下,這沒什麼好擔心的。
非 SEO 抓取機器人
並非所有爬蟲都與 SEO 有關。許多社群平台都經營著自己的機器人。
Meta(Facebook 的母公司)運行多個爬蟲程序,而 Twitter 之前使用過 Twitterbot – 而且 X 現在很可能部署了一個類似但記錄較少的系統。
爬蟲會不斷掃描網路以查找資料。有些可以使您的網站受益,而其他的則應該透過伺服器日誌進行監控。
了解搜尋機器人、SEO 爬蟲和技術 SEO 抓取工具
管理第一方和第三方爬蟲對於維護您網站的技術 SEO 至關重要。
關鍵要點
- 第一方爬蟲(例如,Screaming Frog、Ahrefs、Semrush)有助於審核和優化您自己的網站。
- 透過 Search Console 的Googlebot 洞察提供了索引和效能的關鍵資料。
- 第三方爬蟲(例如 Bingbot、AhrefsBot、SemrushBot)抓取您的網站進行搜尋索引或競爭分析。
- 透過robots.txt和伺服器日誌管理機器人可以幫助控制不需要的爬蟲並在特定情況下提高爬取效率。
- 資料處理技能對於從抓取報告和日誌檔案中提取有意義的見解至關重要。
透過平衡主動審計和策略機器人管理,您可以確保您的網站保持良好的最佳化和高效的抓取。
