如何防止人工智慧竊取您的內容

如何防止人工智慧竊取您的內容
擔心人工智慧竊取您的內容?學習評估風險並保護您的行銷免於抄襲。
人工智慧提供了令人興奮的機會,但也引發了可以理解的擔憂——包括產生人工智慧模型「獲取」或濫用人類作家和行銷人員創建的內容 的可能性。
本文旨在明確定義這些風險,分析人工智慧如何複製或抄襲你的工作的場景,並提供實用的技巧,以在人工智慧驅動的世界中保護自己,同時仍然受益於新興技術。
為什麼我們關心人工智慧奪取我們的內容?
讓我們定義一下我們的術語。當我們談到人工智慧「獲取內容」時,我們實際上是在討論我們作為個人、我們所進行的行銷活動以及我們所創造的工作所面臨的多種不同風險。
為了幫助我們駕馭這個充滿可怕可能性的網絡,我製作了一張圖表,總結了人工智慧獲取內容的幾種方式:
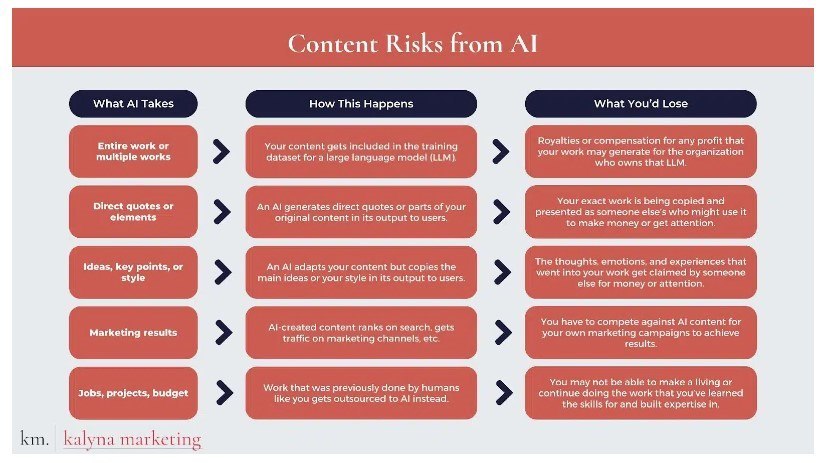
讓我們更詳細地思考所有這些風險。
人工智慧可以從您的內容中獲取什麼?
首先,生成式人工智慧可以從我們身上奪走什麼?我認為我們實際上會失去五類東西:
您的全部作品或多幅作品
生成式人工智慧可以獲得您可能製作的整個作品,例如部落格文章、影片、社交貼文、圖像或上述內容的組合。
生成式人工智慧可能會索引您的整個網站以及您在任何社交媒體帳戶上發布的所有內容。
你的言語或作品的元素
生成式人工智慧可以複製您作品的全部內容,例如直接逐字引用您的內容,包括您創建的圖像,或複製影片中的影格。
這種類型的直接抄襲也可能包括對內容中的文字或顏色進行微小的更改。
您的想法或風格
生成式人工智慧可以透過竊取你內容的想法、格式或美學來更間接地剽竊你。如果你以新的方式結合了一些來源進行了研究,人工智慧可能會突然做出相同的比較。
如果你對SEO的未來進行了巧妙的觀察,生成式人工智慧可能會突然預測出相同的場景,但用它自己的話來說。有人還可以提示生成人工智慧以您的風格創建內容,就像許多工具允許人們做的那樣。
您的行銷成果
生成式人工智慧可以獲得您的內容結果,而不是複製您的作品。
如果人工智慧內容突然淹沒了您所定位的相同查詢的 SERP 排名,或者其他公司開始使用人工智慧生成的貼文來獲取社群媒體來源,您可能會失去受眾。
您也可能難以脫穎而出、贏得信任或轉化為銷售。
您的工作、任務或預算
生成式人工智慧可以透過在沒有你的情況下製作內容來獲取你的內容。你的任務、角色或團隊可能會被削減並被生成式人工智慧所取代,而生成式人工智慧應該可以產生與你這樣的人類相同的內容。
怎麼會發生這種事呢?
但生成式人工智慧怎麼能從我們身上奪走這些東西呢?
如果我們害怕失去某些東西,我們應該了解我們可能失去它的機制。我將這些場景分為四類:
訓練資料
- 您的內容將包含在大型語言模型 ( LLM )的訓練資料集中。
產生對使用者的回應
- 生成式人工智慧在輸出給使用者時產生直接引用或部分原始內容。
- 或者,生成式人工智慧會調整您的內容,但將其輸出中的主要想法或您的風格複製給使用者。
爭取行銷成果
- 人工智慧創建的內容在搜尋上排名,在行銷管道上獲得流量等。
影響經濟和可用工作
- 以前由像您這樣的人類完成的工作被外包給人工智慧。
它會對你產生什麼影響?
失去一些東西總是令人不快,但人工智慧奪走我們的內容會對我們產生什麼影響呢?我認為身為內容行銷人員我們會面臨三種核心傷害:
財務損失
您可能會以以下形式損失金錢:
- 您的作品可能為擁有法學碩士並接受您的內容培訓的組織帶來的任何利潤的版稅或補償。
- 從您的作品被複製並呈現為他人的作品中獲得利潤,無論是透過直接抄襲還是調整您的想法和風格。
行銷、情感和聲譽損失
在以下情況下,您可能會失去認可和機會:
- 您使用的行銷策略和管道不再為您的組織帶來相同類型的回報。
- 你工作中的想法、情感和經驗會被其他人索取以獲取金錢或關注。
- 您必須在自己的行銷活動中與人工智慧內容競爭才能取得成果。
工作成功與保障
若發生以下情況,您作為行銷人員的工作可能會受到影響:
- 當你的任務外包給生成式人工智慧時,你的工作就會被削減或改變。
- 你的團隊被解僱,你的責任增加,因為你需要「利用人工智慧」來產生與整個人類團隊相同的輸出。
- 你的技能會被貶值,因為人工智慧似乎可以在幾秒鐘內以一小部分成本完成相同品質的工作。
其中許多風險並非內容行銷人員所獨有。但是,雖然我們可能會像其他專業人士一樣擔心一些相同的事情,但所有這些傷害都可能以獨特的方式直接影響我們的工作。
另一方面,這些風險是否一定是人工智慧取得我們內容所特有的?無論是人為或軟體剽竊都可能造成損害。人類竊取您的內容與大型語言模型竊取您的內容之間有區別嗎?

另一個人竊取你的內容和產生人工智慧有什麼區別?
簡單的答案是,人類知道自己在做什麼並且可以承擔責任。
人有代理權和自由意志。他們必須主動決定要尋找你的作品,將其中的一部分據為己有,並將其呈現為自己的作品。
另一方面,生成式人工智慧是一種程序,其輸出具有一定程度的隨機性和不可預測性。當生成式人工智慧偷竊時,感覺很意外。
不存在任何罪責,因為人工智慧不可能有犯罪意圖或精神狀態。如果沒有一顆能夠理解其行為後果的大腦,生成式人工智慧就不會對其行為的結果負責。
但這是真的嗎?透過人工智慧進行的抄襲與傳統的 100% 人類抄襲有何不同?讓我們思考一些假設的場景,看看這會引導我們走向何方。
場景 1:老派的人類抄襲
有意識和故意的抄襲是什麼樣子的?
假設一位名叫 Jane Doe 的人類作家決定採用 Semrush 部落格中 Connor Lahey 撰寫的文章「12 SEO Tips to Boost Your Organic Rankings & Traffic」。
Doe 可能會更改標題、簡介和一些標題,然後以她自己的名義在hottestseotipsblog.com上發布。在這種情況下,多伊知道自己在做什麼,並主動選擇將別人的工作扭曲為她的工作。
Doe 將 Semrush 的作品呈現為她自己的原創內容有什麼問題?她的剽竊行為會造成兩種傷害:對塞姆拉什的傷害和對訪問能源部網站的人的傷害。
對原作者的傷害
Doe 傷害了 Semrush,因為當她竊取他們的內容時,她也可能竊取其行銷和業務影響。
美國能源部最終可能會奪走原始作品的流量。她最終可能會:
- 獲得她提出的想法的反向連結和信譽。
- 透過該頁面上顯示的廣告、她可能在文本中包含的附屬連結或該內容產生的商機來賺錢。
照理說,錢和流量應該流向原作者和 Semrush 網站。
對觀眾的傷害
Doe 傷害了造訪她網站的人,因為她扭曲了自己的專業知識。透過在該內容上署上自己的名字,Doe 給人一種錯誤的印象,即該網頁上的文字是她最初的想法和經驗。
Doe 可能會出售 SEO 諮詢服務,她可以吸引那些閱讀了抄襲文章、喜歡她的見解並根據該內容隱含的知識決定僱用她的客戶。從本質上講,透過抄襲塞姆拉什的作品,多伊正在竊取信任和可信度。
場景 2:在沒有監督的情況下僱用代筆人
假設 Doe 沒有抄襲現有的內容,而是聘請了一位代筆作家為她撰寫內容。她告訴代筆人,她需要一篇主題為「10 個最佳 SEO 技巧」的部落格文章,並且她希望它的長度約為 2,000 字。
當作者發送完整的草稿後,Doe以她自己的名義將其發佈在hottestseotipsblog.com上。這是抄襲嗎?
即使作者將該作品完全視為其原創作品,我們也可以認為場景 1 中的相同危害仍然存在:
對原作者的傷害
代筆作者可能不會因在能源部網站上發布該文章而獲得任何收入。
他們可能不被允許在他們的投資組合中使用這些內容,並失去獲得更多客戶的機會,即使他們的作品起飛並變得流行。
對大眾來說,原作者是隱形的,從功能上來說並不存在。
對觀眾的傷害
任何造訪 hottestseotipsblog.com 的使用者仍然會被認為 Doe 是該內容的作者。多伊仍然從不屬於她的想法和技能中藉用信譽和信任。
注意:代筆安排很常見。如果作者同意放棄任何信用或額外的費用補償,他們應該被允許這樣做。
這種情況不一定是“竊取”,但它仍然歪曲了誰做了創建該內容的工作。這是抄襲還是可接受的做法取決於我們自己的定義和道德。
另一方面,如果作者實際上從 Semrush 這樣的現有來源複製了這篇文章,那麼這篇文章絕對是抄襲。在這種情況下,我們可以說能源部負責交叉檢查最終草案並確保其是原創作品。
但大部分責任應由代筆人承擔,他們向多伊歪曲內容為自己的原創作品。
場景 3:產生抄襲報價的通用 AI 提示
當人工智慧介入時會發生什麼?
也許 Doe 可能會打開 ChatGPT 並提示如下內容:
- 「您是一位 SEO 專家,熟悉內容創建、行銷、技術 SEO、關鍵字研究和專業受眾寫作的最佳行業實踐。為主題“10 個最佳 SEO 技巧”起草一篇完整且原創的部落格文章,其中包含 1-3 級副標題和具體示例。
假設在我們的場景中,ChatGPT 已接受 Semrush 部落格內容的訓練。當 ChatGPT 為 Doe 產生部落格文章時,草稿會複製 Semrush 文章中的整個段落和大部分要點,並附有 12 個 SEO 技巧。
如果 Doe 保持人工智慧創建的草稿不變,並以她自己的名字將其發佈在hottestseotipsblog.com上 – 她是否抄襲?
最終結果與我們的第一個場景相同 – 現在在另一個網站上以 Jane Doe 的名義發布了一篇部落格文章,使用與 Semrush 網站上的文章完全相同的文字。
Hottestseotipsblog.com可能不包含任何內容是在人工智慧的幫助下製作的免責聲明。它如何融入我們的框架?
對原作者的傷害
在這種情況下,Semrush 仍在失去潛在的流量、收入和其他商機。
對觀眾的傷害
對於任何造訪 Doe 網站的使用者來說,該內容看起來完全是原創的,並且是根據 Doe 自己的專業知識編寫的。
然而,將與第一種情況相同程度的責任歸咎於能源部感覺並不正確。畢竟Doe並不知道她發表的內容是抄襲的。
她可能從未見過塞姆拉什的作品。她可能真誠地相信 ChatGPT 為她提供了一篇從未在其他地方發表過的完全原創的部落格文章。
然而,多伊仍然扭曲了她的工作。這篇文章不是她寫的,而是 ChatGPT 寫的。 Doe 可能不是故意抄襲 Semrush,但她確實竊取了 ChatGPT 的專業知識及其訓練資料。
場景 4:特定AI提示複製某人風格
如果 Doe 打開 ChatGPT,複製 Semrush 文章的文本,並寫下以下提示:
- 「為主題「10 個最佳SEO 技巧」起草一篇完整且原創的部落格文章,其中包含1-3 級副標題和具體示例,其風格與以下文本相同[粘貼的「12 個SEO 技巧,以提高您的有機排名和流量”的文本來自塞姆拉什]”
在這種情況下,ChatGPT 可能不會複製 Semrush 的任何確切措辭或要點。但相反,多伊要求人工智慧從塞姆拉什的作品複製更模糊的風格和格式概念。
ChatGPT 的輸出聽起來仍然與 Semrush 類似,其中一些想法甚至可能與原始版本相呼應。
儘管更難確定,但多伊仍然在偷東西。那麼,它如何融入我們的框架呢?
對原作者的傷害
Semrush 的原創內容仍未被認可。風格是努力工作、寫作技巧和創造力的結果。 Doe 未經許可就採取了這種做法,她產生的任何流量或收入仍然依賴不屬於她的東西。
對觀眾的傷害
多伊將這些風格選擇呈現為她自己的風格,並可能被認為是一個比她實際上更好的作家或思想家。
如果 Semrush 的文章有一個特別獨特的結構並且 ChatGPT 複製了它,那麼 Doe 就會從現在看來屬於她自己的多種創意選擇中受益。
當然,複製別人內容的風格可以被描述為靈感。但如果沒有註明出處,並且嚴重依賴靈感,以至於兩件作品彼此相似,那仍然可能是抄襲。
Doe 對這種抄襲行為負有一定程度的責任——她直接促使 ChatGPT 複製他人內容的風格。
場景 5:特定的AI提示來解釋某人的想法
如果 Doe 提示 ChatGPT 直接從 Semrush 複製想法會怎麼樣?她可以寫一個這樣的提示:
- “改編以下文字並將其改寫為一篇完整且原創的部落格文章,主題為“10 個最佳 SEO 技巧”,副標題為 1-3 級。保持相同的想法,但以相同的風格起草您自己的獨特示例:[粘貼來自 Semrush 的“提高有機排名和流量的 12 個 SEO 技巧”文本]”
與場景 4 一樣,在生成人工智慧提示中包含「原創」一詞並不會神奇地消除竊取他人的意圖。
Doe 敦促 ChatGPT 直接複製他人的原創作品,並明確要求其不僅複製 Semrush 作品的風格,還複製其要點。
即使最終草案中的所有單字和短語都不同,最終的文章仍然是抄襲。
以下是它如何適合我們的框架:
對原作者的傷害
塞姆拉什和文章作者仍然沒有從他們的工作中獲得任何榮譽、認可或收入。
原作者可能花在創作這篇文章、思考想法、探索 SEO 最佳實踐和收集資訊上的任何時間的研究——這些都只是 Doe 為了她自己的利益而使用的。
她在搶佔功勞的同時,也竊取了創作優質內容所需的時間和精力。
對觀眾的傷害
任何讀過多伊的文章的人仍然會相信這是她自己的。
讀者會信任 Doe,不僅因為她準確的用詞選擇,還因為她對 SEO 的深刻理解以及向他人解釋最佳實踐的能力。
當多伊從塞姆拉什那裡竊取想法時,她竊取了所有這些含義,即使確切的措辭發生了變化。
在這種情況下,抄襲的大部分責任都在 Doe 身上。
此場景與場景 1 幾乎相同:Doe 故意選擇從 Semrush 複製內容,並進行一些修改後將其呈現為她自己的內容。
唯一的區別是她使用的方法:在場景 1 中,Doe 手動進行了這些修改,在這種情況下,Doe 使用 ChatGPT 為她做這些骯髒的工作。
場景 6:建立生成式 AI 模型以根據現有內容撰寫部落格文章
在我們的討論中,我們沒有提到涉及人工智慧的場景中的一個關鍵方:首先建立人工智慧模型的人。
假設 Jane Doe 實際上是一位熟練的開發人員,可以建立自己的機器學習應用程式。她構建了自己的演算法,可以打亂並自動解釋語言。然後,Doe 提示演算法使用 12 個 SEO 技巧重新表述 Semrush 部落格文章。這是抄襲嗎?
從功能上講,此場景與場景 5 相同。
如果 Doe 建立了一個演算法,對 Semrush 的所有部落格文章進行訓練,然後要求它產生「10 個最佳 SEO 技巧」草稿,結果會怎麼樣?
在這種情況下,Doe 並不是竊取一篇文章。然而,她的軟體仍在重新整理和解釋 Semrush 的語言和想法。最終的作品仍然是抄襲的,但要確定每個部分的來源變得更加困難。
現在,假設 Doe 取得了 Semrush 的所有部落格內容,還包括來自 Ahrefs、Moz、Search Engine Land 和其他 50 個 SEO 網站的部落格文章。
她使用所有這些內容來培訓自己的法學碩士,然後提示人工智慧產生一篇包含「10 個最佳 SEO 技巧」的部落格文章。然後,Doe以自己的名義在hottestseotipsblog.com上發布了人工智慧創作的文章。這個場景如何適合我們的框架?
對原作者的傷害
我們現在正在與多位原作者打交道,而不僅僅是 Semrush。但所有在訓練資料集中使用其內容的網站都在某種程度上複製了其想法、風格和單字選擇。
Doe 的作品仍可能為她的網站帶來收入、商機和流量。並且沒有任何原始作者和網站因這些結果而得到認可或補償。
對觀眾的傷害
任何造訪 Doe 網站的人仍然認為向他們提供的內容反映了 Doe 的原創作品、想法和專業知識。
當然,能源部已經努力建構生成內容的人工智慧。但是,如果讀者只是閱讀 SEO 技巧,而不了解 Doe 的人工智慧軟體的複雜性,那麼讀者是否真的見證了 Doe 自己的工作?
歸根結底,如果有人因為這些內容而認為 Doe 是 SEO 專家,Doe 仍然會竊取其他人的信任。她的 SEO 建議都不是她自己的。美國能源部值得稱讚的是他創造了一台奇特的竊取機器,而不是它產生的內容。
無論是否涉及人工智慧,抄襲都是一樣的
是否涉及人工智慧並不重要:正如我們從上面概述的場景中看到的那樣,當人類將他人的工作歸功於自己時,剽竊總是由人類完成的。人工智慧只是一種提供竊取內容新方式的技術,但它並沒有從根本上創造出一種全新的剽竊或內容創作類型。
你可以把人工智慧想像成一個特別高科技的攪拌機:你可以把一堆碎片塞進去,按下按鈕,然後得到均勻的混合物,然後發佈到你自己的網站上。但該混合物仍然由您放入其中的相同內容組成。
攪拌機不會創造任何新東西。它只是將一些預先存在的物質以不同的形式呈現。如果你做胡蘿蔔冰沙,你能說這些胡蘿蔔是你種的嗎?對於內容也是如此。
如果您擔心人工智慧會竊取您的內容,請記住看看幕後到底是誰在幕後操縱。雖然軟體本身可能不會產生犯罪心理狀態,但創建或促使它的人肯定會。人工智慧無法竊取你的東西,但使用人工智慧的人類可以。
我們如何才能最大限度地減少人工智慧對我們的內容帶來的風險?
好吧,所有這些聽起來都非常令人沮喪。您可能已經準備好放棄行銷這個概念了。我不怪你——人工智慧對我們的內容的威脅是可怕的。
人們混淆自己竊取內容、想法或工作的罪責的方式是危險的。使用生成式人工智慧的人可能會對你、我或我們共事和關心的許多人造成真正的傷害。
然而,這並不意味著我們應該放棄。只要還有可以竊取的想法,人類就一直在竊取想法。就像我們有辦法打擊老式的人類剽竊行為一樣,我們也可以努力防止人工智慧輔助的剽竊行為。
最後,讓我們看看如何最大限度地降低風險並減少生成式人工智慧對我們內容的危害。
不,「成為生成式人工智慧專家」並不是解決方案
在我深入討論具體建議之前,有一個簡短的免責聲明:我不會建議您成為生成式人工智慧專家或學習如何使用機器學習。
當然,這些技能可能很有價值。但它們分散了我們正在努力解決的真正問題的注意力:
- 在沒有人工智慧的世界中,我們如何保護我們作為內容行銷人員所做的工作和技能?
人工智慧與任何技術一樣,都會對我們可以完成的任務類型產生一些影響。但這並沒有改變「行銷」或「內容」的本質。
說只有了解人工智慧才能繼續當行銷人員,就等於告訴你必須徹底改變職業。生成人工智慧專家不是行銷人員。行銷人員也可能是產生人工智慧專家,而產生人工智慧專家可能是內容專家。
但這些職業不可互換,而且它們背後的技能也各不相同。可以這樣想:時不時使用 Excel 來準備報表會讓你成為資料分析師嗎?可能不會。
即使人工智慧成為我們工作方式的核心部分,我們作為行銷人員所做的工作仍然有價值。因此,當我們考慮最大限度地降低人工智慧獲取我們內容的風險時,我們應該特別考慮行銷工作的獨特技能和挑戰。
選擇退出 AI 抓取以避免經濟損失
您可以做的第一件事就是防止您的內容出現在某些人工智慧資料集中。這是最暴力的選擇,對於大多數行銷人員或網路發布者來說並不實用。
請記住,選擇退出任何人工智慧索引也意味著您的網站和任何相關資訊不會出現在該人工智慧的輸出中。如果任何用戶透過提示生成人工智慧聊天機器人來查找有關您的業務的信息,他們可能不會在結果中看到您。
透過這種方式保護您的隱私,您實際上是在犧牲生成式人工智慧作為行銷管道。因此,請確保您已準備好承擔採取該步驟的任何後果。
您可以透過將以下行新增至 robots.txt 檔案來選擇退出 OpenAI 的GPTBot 抓取:
“User-agent: GPTBot
Disallow: /”您也可以使用Google 擴充功能控制來阻止 Google 的 Bard 和 Vertex AI ,方法是將以下內容新增至 robots.txt 檔案:
“User-agent: Google-Extended
Disallow: /”遺憾的是,Google 擴充功能不會阻止您的網站在 Google 的 AI 支援的搜尋生成體驗 (SGE) 中建立索引。似乎避免出現在 SGE 中的唯一方法是完全退出 Google 索引。
您可以在Google 自己的文件中了解有關 Google 抓取工具和編輯權限的更多資訊。
其他一些發布工具可能允許您在平臺本身內控制這些設定。例如,Substack 在其編寫器儀表板中包含一個「阻止人工智慧訓練」的設定。
這似乎主要是讓您選擇退出 GPTBot,但也許它將來會成為更強大的攔截器。

透過轉向難以複製的行銷方法來重新獲得行銷優勢
對我們大多數人來說,阻止人工智慧爬蟲或完全退出搜尋引擎優化並不是一個選擇(否則,為什麼你會在搜尋引擎土地上閱讀這篇文章?)。那麼,我們能做什麼呢?
接受有人可能會嘗試使用人工智慧抄襲您的內容。即使您可以選擇退出每個訓練資料集,有人仍然可以將您的工作複製並貼上到 ChatGPT 中並以這種方式竊取。
當有人想偷東西時,他們就會找到辦法。試圖防止您的內容被複製將很快變成一場無休止的打地鼠遊戲,或導致您完全停止在開放網路上發布。
即使其他人複製您的內容,您如何減少傷害?透過思考難以複製(如果不是不可能的話)的行銷方法。
如果 Jane Doe 確實從 Semrush 那裡偷了一篇文章,而您又看到了該文章的兩個版本 – 您會更相信誰?如果您是行銷人員,您可能已經熟悉 Semrush 這家公司和值得信賴的資訊來源。
當看到被抄襲的內容時,您可能會認為 Semrush 是原作者。即使 Semrush 可能會損失一些流量或收入,從長遠來看,Jane Doe 也無法竊取他們的品牌、聲譽、內容創建流程、團隊或經驗。
其他人也許能夠竊取你的一些工作,但他們無法竊取你的專業知識。如果您的內容真正原創、值得信賴且有幫助—人們將繼續信任您。
您可以繼續:
- 製作能夠賺取流量的內容。
- 利用多種行銷管道。
- 建立您自己的品牌和組織內人員的個人聲譽。
沒有人工智慧可以竊取它。
依靠你的人性來保護你的工作和預算
人工智慧或其他人類無法從你身上奪走的你的本質是什麼?
是什麼讓你,作為個人、部門或組織──成為你?從您獨特的經驗、定位和人脈融合中挖掘您真正的差異化優勢。
其他人可能能夠複製您的想法或自動化您的某些技能。但如果你的工作或行銷計畫是建立在你的基本人性和獨特觀點之上,它們就不會被取代。
如果你想在人工智慧面前保持彈性,就保持人性。投資真正的思想領導、發展關係、表達強烈的意見以及講述只有你能講的故事。
不要放棄人工智慧——行銷不會有任何進展
人類信任其他人。儘管目前有很多炒作,但人工智慧不會改變這一點。小偷也許可以藉用你的聲譽,但真正的專業知識總是會暴露出來。抄襲者將無法借鏡您的想法或重現您的成功。
因此,如果您擔心人工智慧會竊取您的內容,請確保您繼續建立值得竊取的內容,因為您首先創建優質內容的能力將是您可能擁有的最佳防禦。
