理解並解決“已發現 – 當前未編入索引”

理解並解決“已發現 – 當前未編入索引”
了解您在 Google Search Console 中看到此狀態的潛在原因,以及解決相關抓取和索引問題的方法。
如果您在Google Search Console中看到「已發現 – 目前未編入索引」,則表示 Google 已知道該 URL,但尚未對其進行抓取和編入索引。
這並不一定意味著該頁面永遠不會被處理。正如他們的文檔所說,他們可能會稍後再回來,而不需要你付出任何額外的努力。
但其他因素可能會阻止 Google 抓取和索引該頁面,包括:
- 伺服器問題和頁面技術問題正在限制或阻止 Google 的抓取能力。
- 與頁面本身相關的問題,例如品質。
您也可以使用Google Search Console Inspection API對 URL 進行排隊以查看其coverageState狀態(以及其他有用的資料點)。
透過 Google Search Console 請求索引
這是一個顯而易見的解決方案,在大多數情況下,它可以解決問題。
有時,Google 抓取新 URL 的速度很慢。它發生了。但有時,潛在的問題才是罪魁禍首。
當您要求索引時,可能會發生以下兩種情況之一:
- URL 變成「已抓取 – 目前未編入索引」。
- 臨時索引。
兩者都是潛在問題的症狀。
第二種情況的發生是因為請求索引有時會為你的 URL 帶來暫時的“新鮮度提升”,這會使 URL 達到必要的品質閾值,進而導致臨時索引。
頁面品質問題
這就是詞彙容易讓人困惑的地方。有人問我,“如果網頁還沒有被抓取,Google 如何確定網頁品質?”
這是一個好問題。答案是不能。
Google 會根據網域中其他頁面來判斷該頁面的品質。它們的分類同樣是基於 URL 模式和網站架構。
因此,將這些頁面從「意識」移至抓取佇列可能會因在類似頁面上發現的品質不足而被降低優先順序。
與其他針對相同使用者意圖和關鍵字的內容相比,具有相似 URL 模式的頁面或位於網站架構相似區域的頁面可能具有較低的價值主張。
可能的原因包括:
- 主要內容深度。
- 推介會。
- 支援內容的等級。
- 所提供內容和觀點的獨特性。
- 或甚至更多的操縱問題(即內容品質低且自動產生、旋轉或直接複製已建立的內容)。
努力提高網站叢集和特定頁面的內容質量,可以對重新激發 Google 更有目的地抓取您的內容的興趣產生積極影響。
您也可以對網站上您承認品質不是最高的其他頁面不編制索引,以提高網站上優質頁面與劣質頁面的比例。
抓取預算和效率
抓取預算是 SEO 中常被誤解的機制。
大多數網站不需要擔心這一點。
谷歌的 Gary Illyes 公開聲稱,大概90% 的網站不需要考慮抓取預算。這常常被認為是企業網站的問題。
另一方面,爬行效率會影響各種規模的網站。如果忽略這一點,可能會導致 Google 抓取和處理網站的方式出現問題。
舉例來說,如果您的網站:
- 帶有參數的重複 URL。
- 有或沒有尾部斜線均可解決。
- 可在 HTTP 和 HTTPS 上使用。
- 提供來自多個子網域的內容(例如,https://website.com 和 https://www.website.com)。
……那麼您可能會遇到重複問題,這會影響 Google 基於更廣泛的網站假設對抓取優先順序的假設。
您可能會因為不必要的 URL 和請求而浪費 Google 的抓取預算。
由於 Googlebot 是分部分抓取網站的,這可能會導致 Google 的資源不足以以您想要的速度發現所有新發布的 URL。
您需要定期抓取您的網站,並確保:
- 頁面解析到單一子網域(根據需要)。
- 頁面解析為單一 HTTP 協定。
- 帶有參數的 URL 被規範化為根(根據需要)。
- 內部連結不需要使用重定向。
如果您的網站使用參數(例如電子商務產品過濾器),您可以透過在robots.txt 檔案中禁止這些 URI 路徑來限制對這些 URI 路徑的抓取。
您的伺服器對於 Google 如何分配預算來抓取您的網站也起著重要作用。
如果您的伺服器超載且回應太慢,則可能會出現抓取問題。
在這種情況下,Googlebot 將無法存取該頁面,導致您的部分內容無法被抓取。
因此,Google 可能會稍後再嘗試對該網站進行索引,這無疑會導致整個過程的延遲。
抓取和索引之間的關係
多年來,我們一直相信抓取和索引之間存在可量化的關係。
多年來,我們發現,如果 URL 每 75 到 140 天沒有被抓取一次,它們就會「從索引中掉出來」。
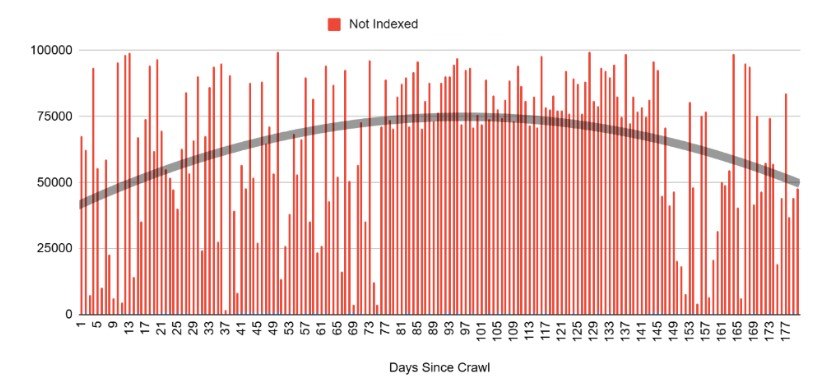
差異可能取決於 URL 的「受歡迎程度」和「需求量」。
上面的圖表是我在 4 月的技術 SEO 高峰會上分享的,它顯示了數百萬 URL 網站的 URL 索引曲線及其與上次抓取日期的相關性。
SEO 產業共享的新數據將「130 天」定義為基準,這與我們多年來看到的敘述一致。
內部連結
當您擁有一個網站時,從一個頁面到另一個頁面 建立內部連結非常重要。
Google 通常較少關注沒有任何或沒有足夠內部連結的 URL,甚至可能將其排除在索引之外。
您可以透過 Screaming Frog 和 Sitebulb 等爬蟲檢查頁面內部連結的數量。
優化您的網站需要一個有組織的、合乎邏輯的網站結構和內部連結。
但是如果您遇到此問題,請確保所有內部頁面都已連接的一種方法是使用 HTML 網站地圖「侵入」抓取深度。
這些是為使用者設計的,而不是為機器設計的。儘管它們現在可能被視為文物,但它們仍然有用。
此外,如果您的網站有許多 URL,最好將它們分成多個頁面。您不希望它們全部連結到一個頁面。
內部連結也需要使用<a>內部連結標籤,而不是依賴諸如 之類的 JavaScript 函數onClick()。
如果您正在使用 Jamstack 或 JavaScript 框架,請研究它或任何相關函式庫如何處理內部連結。這些必須以 <a> 標籤的形式呈現。
